共计 2490 个字符,预计需要花费 7 分钟才能阅读完成。
R 语言及其扩展的开发是怎样的,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
简介
R 是一门主要用于统计分析、绘图的语言和环境,是 S 语言的一种实现,但 R 的语法却是来自 Scheme,是一种面向对象、支持反射的函数式脚本语言。
R 本来是由来自新西兰奥克兰大学的 Ross Ihaka 和 Robert Gentleman 开发,随即成为 GNU 的项目之一,现在由 R 开发核心团队 负责开发。R 现在支持多种平台,包括 GNU/Linux、FreeBSD、Windows 和 MacOS。
作业环境
与其它商业统计软件不同,R 主要的用户交互接口是 R 解析器。用户可以与 R 如同与 shell 一般灵活交互,也可以通过脚本向 R 提交作业。R 提供 libR.so 共享对象,开发者可以设计 GUI 前端并与之连接,这样既能够提供 R 解析器接口又能提供丰富的菜单功能和其它作业方式。
在 *nix 上,vim 和 (x)emacs 是著名的两大编辑器,相应地,开发者提供了 R 的交互支持:
ESS (Emacs Speaks Statistics)
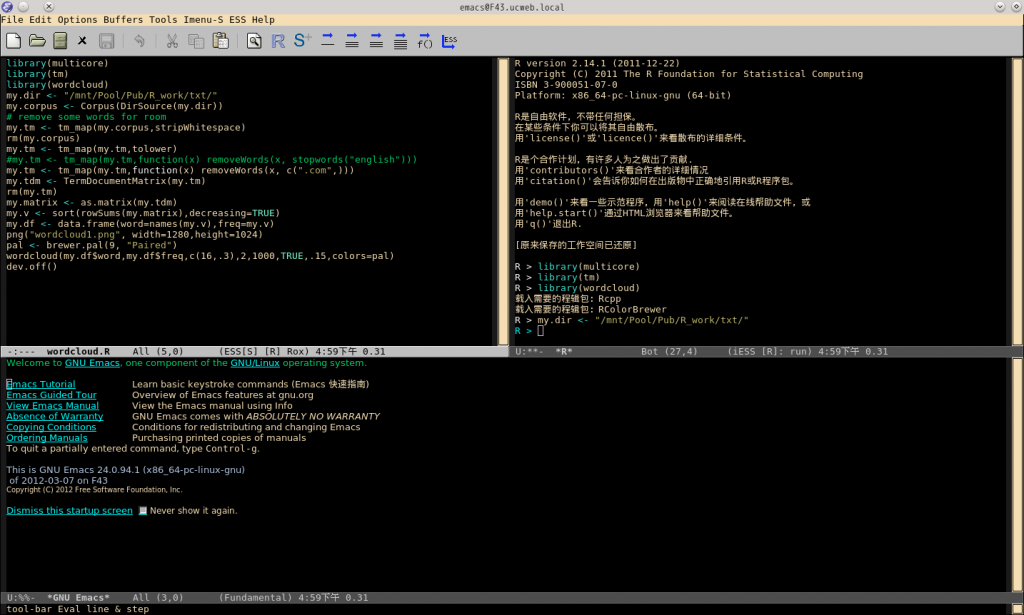
Vim-r
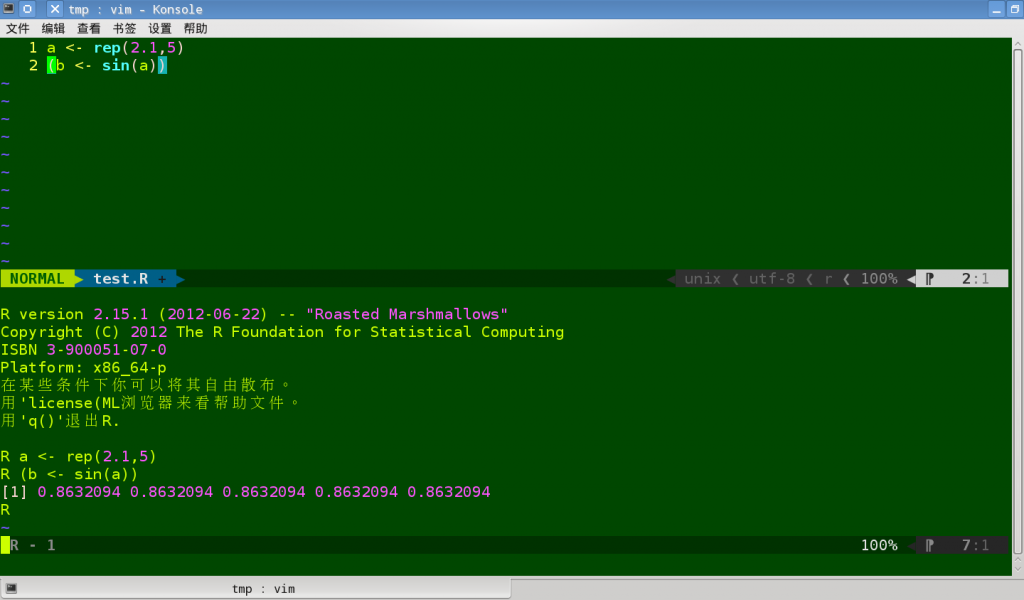
作为 KDE 桌面的原生程序,RKWard 提供了良好的 IDE 体验!

使用
这里我们推荐读者参考 R 的官方参考手册。
为什么使用 R
为什么要使用 R?撇开 R 是自由软件不说,还有以下原因:
R 逐渐成为统计软件的事实标准,在很多方面已经赶上甚至超越 SAS 和 SPSS 等商业软件。
R 的语法简答而清晰
R 的效率很高(主要取决于 BLAS 的实现)
CRAN 有丰富的扩展包
除了原生的 C 接口,R 还有良好的语言绑定,如 C ++,Java,方便用户设计自己的计算敏感的程序
R 支持 OpenMP 和 OpenMPI 等并行基础,适合计算敏感的场合
编写扩展
在上文提及了 R 有良好的语言绑定,其中扩展包 Rcpp 方便用户使用 C ++ 来开发扩展。我们使用 Rcpp 开发了两个实验性的项目 RcppKmeans 和 RcppNaiveBayes,用于数据挖掘的研究。
创建基于 Rcpp 扩展
显然,我们需要安装 Rcpp,注意确保 GCC 和 R 的开发环境是完备的:
install.packages(Rcpp)转移到你的工作目录
library(Rcpp)
Rcpp.package.skeleton(MyProjectName)
OK! MyProjectName 的骨架建好了,开始写代码!等等,建议按照目录里的 Read-and-delete-me 的指示走一遍。
RcppKmeans
为一简单的用于文本的 kmeans 聚类器,通过应用 OpenMP 技术,在多核平台上利用并行带来的优势。
安装
git clone git://github.com/ucweb/RcppKmeans.git
R CMD INSTALL RcppKmeans示例
1 library(RcppKmeans)
2 # 9 个点
3 s - list(
4 c(a , a , b , b ),
5 c(b , b , a , c),
6 c(e , e , f , f),
7 c(t , t , f , f),
8 c(s , t , h , f),
9 c(s , t , h , f),
10 c(s , t , h , f),
11 c(s , t , h , f),
12 c(s , h , t , f))
13 Kmeans(s,4L,1e3L,0.25)输出:
$clusters
$clusters[[1]]
[1] 7 4 5 6 8
$clusters[[2]]
[1] 1 0
$clusters[[3]]
[1] 2
$clusters[[4]]
[1] 3
$iterations
[1] 2
$divergent
integer(0)输出结果说明:
c(a , a , b , b) 和 c(b , b , a , c) 被归入第二个聚类,c(e , e , f , f) 和 c(t , t , f , f) 被孤立,而剩余的则归入第一个聚类。
RcppNaivebayes
为一简单的用于文本的分类器,本身不应用并行技术,但提供的接口可以与 Rmpi 一同使用,从而实现并行处理。
安装
git clone git://github.com/ucweb/RcppNaiveBayes.git
R CMD INSTALL RcppNaiveBayes示例
1 library(RcppNaiveBayes)
3 a - list(c( A , B , B , D , A , Z),
4 c(C , B , C , Z , H))
5 b - list(c( A , F , Y , F , W),
6 c(I , A , G , F , P , D),
7 c(G , A , N , P))
8 d - list(c( Y , D , P),
9 c(H , H),
10 c(Z , Z))
11 m - NaiveBayesTrain(list(a,b)) # 训练两个类别
12 NaiveBayesPredict(m, d)输出:
$scores
$scores[[1]]
[1] 0.1000000 0.2666667
$scores[[2]]
[1] 0.40000000 0.06666667
$scores[[3]]
[1] 0.90000000 0.06666667
$predicted
[1] 2 1 1
attr(, class)
[1] RcppNaiveBayesPredict输出结果说明:
$predicted 的值为 d 各元素被归入的类别,即 c(Y , D , P) 以分值 0.2666667 0.1000000 而归入类别 b;同理,c(Z , Z) 被归入类别 a。
R 是一门十分容易掌握的语言,加之扩展的便捷开发,它迅速在计算相关领域日益得到重视,很多企业级的应用也有 R 的一席之地。然而 R 并非万能,加之并行计算并没有统一模式,以及数据规模的爆炸性增长给予 R 的 in-memory 计算方式极大的冲击。如果要将 R 应用于大数据领域,那么还有一段路要走,尽管商业方案的 RevoScale 提供了解决之道。
关于 R 语言及其扩展的开发是怎样的问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注丸趣 TV 行业资讯频道了解更多相关知识。











