共计 3742 个字符,预计需要花费 10 分钟才能阅读完成。
这篇文章主要介绍了 Ganglia 与 Nagios 如何整合,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让丸趣 TV 小编带着大家一起了解一下。
基本介绍
Ganglia:Ganglia 是 UC Berkeley 发起的一个开源集群监视项目,设计用于测量数以千计的节点。Ganglia 的核心包含 gmond、gmetad 以及一个 Web 前端。主要是用来监控系统性能,如:cpu、mem、硬盘利用率,I/ O 负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性能起到重要作用。
Nagios:Nagios 是一款开源的电脑系统和网络监视工具,能有效监控 Windows、Linux 和 Unix 的主机状态,交换机路由器等网络设置,打印机等。在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知。
架构
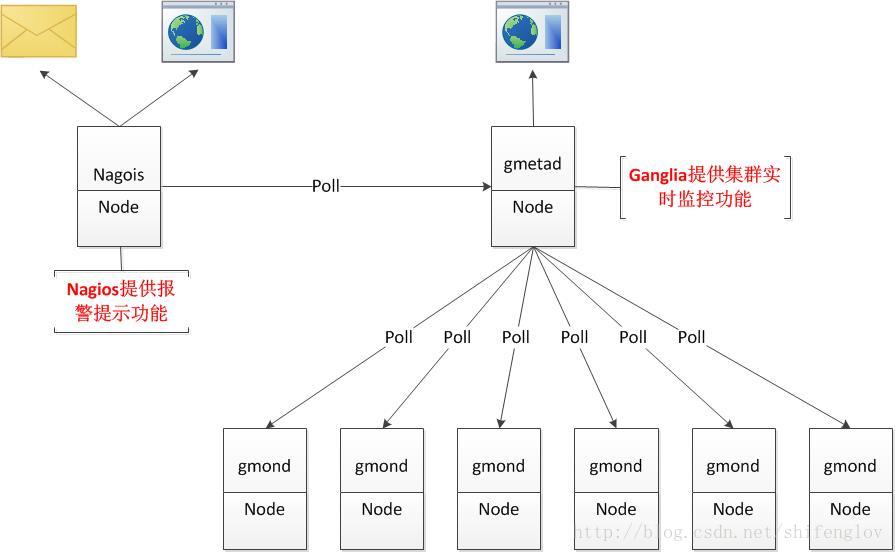
Ganglia 的优势在于实时监控集群中的机器的各项指标,比如 cpu,内存,磁盘,温度等数据,汇总成成各种图形化界面,并提供接口可供调用数据。而在出现问题的时候报警提示功能,相对较弱。
Nagios 的优势在于出现问题之时可以提供强大的报警提示功能,但是在实时监控上,功能较弱,即使使用 NRPE 本地插件也不能提供强大的机器监控。
在集群运维中,有两种方式,第一种,当问题出现的时候能够得到报警提示,运维人员能够迅速出击解决问题,将损失减少到最少。第二种,在问题出现之前,找到可能出现的问题,解决问题,避免问题出现。
因此 Nagios 适合第一种场景,Ganglia 适合第二种场景,两者结合能有效的解决各种场景。当然还有其他的监控报警软件,比如 Monitorix,NetXMS,cacti,Zabbix 等。
这里,我们选择最成熟的 Ganglia 和 Nagios。
环境介绍
1. 集群中已经安装了 Ganglia(安装过程可以参考我的上一篇博客 http://blog.csdn.net/shifenglov/article/details/40587527)
2. 集群中已经安装了 Nagios(安装过程可以参考这篇博客 http://www.cnblogs.com/mchina/archive/2013/02/20/2883404.html)
安装思路
通过 Nagios 调用 Ganglia 的接口,获取整个集群的监控指标,如果超过设定的报警阀值,则予以报警提示。
安装过程
1. 复制 check_ganglia.py 脚本到 nagios 的执行目录中
如果有源码,则 check_ganglia.py 在 ganglia-3.6.0/contrib/check_ganglia.py 中
如果没有源码,则可以下载 check_ganglia.py,很容易搜到
#cp check_ganglia.py/usr/local/nagios/libexec/
#!/usr/bin/env python
import sys
import getopt
import socket
import xml.parsers.expat
class GParser:
def __init__(self, host, metric):
self.inhost =0
self.inmetric = 0
self.value = None
self.host = host
self.metric = metric
def parse(self, file):
p = xml.parsers.expat.ParserCreate()
p.StartElementHandler = parser.start_element
p.EndElementHandler = parser.end_element
p.ParseFile(file)
if self.value == None:
raise Exception(Host/value not found)
return float(self.value)
def start_element(self, name, attrs):
if name == HOST :
if attrs[NAME]==self.host:
self.inhost=1
elif self.inhost==1 and name == METRIC
修改好以后(注意上面文件中 ganglia_host 及 ganglia_port 变量修改)
./check_ganglia.py 试一下,没问题
-h 指定主机。在这里需要注意的是,这里填写的是主机名。前提是 IP 可以被解析。
在 /var/lib/ganglia/rrds/my cluster/ 里面可以看到相应的主机名
-m 检测的是什么参数,在 rrds 目录下可以看到。命令中不带.rrd
-w warning
-c critical
例如
./check_ganglia.py -h 10.20.1.131 -m load_one -w 4 -c 5
2. 追加获取 ganglia 数据命令
#vim /usr/local/nagios/etc/objects/commands.cfg
追加内容如下:
define command {
command_name check_ganglia
command_line $USER1$/check_ganglia.py -h $HOSTADDRESS$ -m $ARG1$ -w $ARG2$ -c $ARG3$
}3. 追加监测数据所在主机信息(文件为新追加)
#vim /usr/local/nagios/etc/objects/hosts.cfg
文件内容如下:
define host{
use linux-server
host_name test
address 10.20.1.131
define hostgroup{
hostgroup_name ganglia-servers
alias ganglia-servers
members test
}4. 追加监测 metrics 信息 (文件为新追加)
#vim /usr/local/nagios/etc/objects/services.cfg
文件内容如下:
define servicegroup{
servicegroup_name ganglia-metrics
alias Ganglia Metrics
define service{
use ganglia-service
host_name test
hostgroup_name ganglia-servers
service_description load_one
check_command check_ganglia!load_one!4!5
define service{
use ganglia-service
host_name test
hostgroup_name ganglia-servers
service_description mem_free
check_command check_ganglia!mem_free!50000!40000
}5. 追加模板信息
#vim /usr/local/nagios/etc/objects/templates.cfg
追加内容如下:
define service {
use generic-service
name ganglia-service
hostgroup_name ganglia-servers
service_groups ganglia-metrics
register 0
}6. 追加配置文件关联
#vim /usr/local/nagios/etc/nagios.cfg
追加内容如下:
# 引进 host 文件
cfg_file=/usr/local/nagios/etc/objects/hosts.cfg
#引进监控项的文件
cfg_file=/usr/local/nagios/etc/objects/services.cfg7. 修改 gmetad 配置,使其 share 监控数据
因为默认情况下,ganglia 的 gmetad 服务不会 share 监控指标给网络上的其他机器,默认只能把数据传输到 localhost,所以需要做相应的配置,使其可以 share 相应数据给其他机器。主要是考虑 nagios 的主机与 ganglia 的主机没在同一台机器上。
# vi /etc/ganglia/gmetad.conf
修改内容如下:
trusted_hosts 10.20.1.158 ## 添加信任的主机 IP8. 重启 ganglia 及 nagios 服务
ganglia:
#service ganglia-monitor restart
#service gmetad restart
nagios:
#service nagios restart
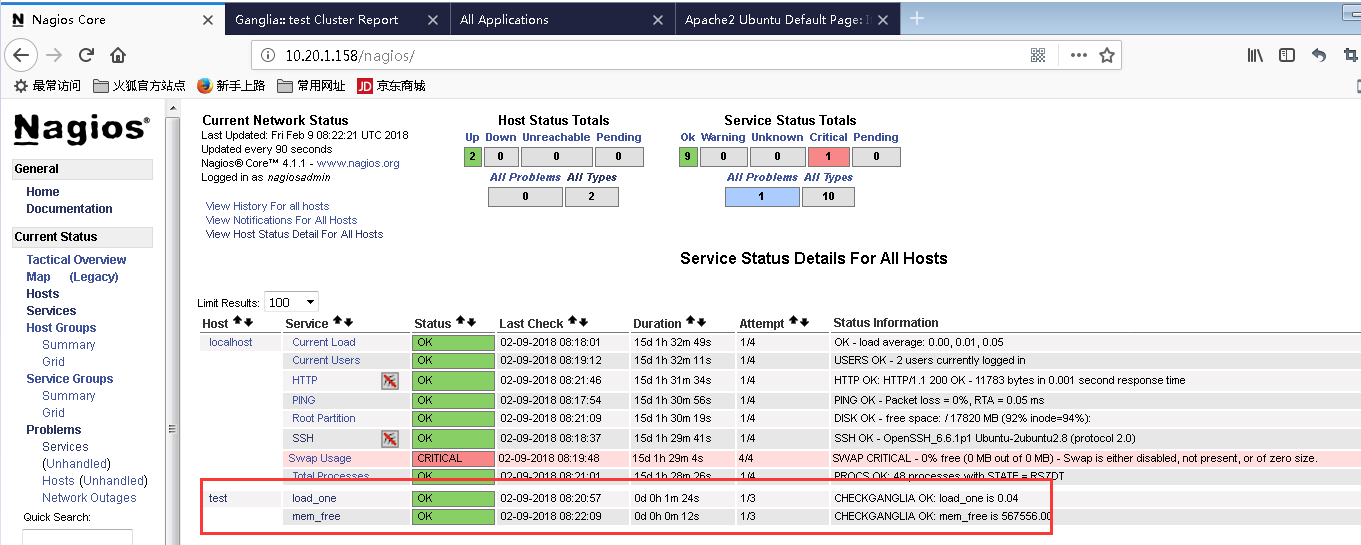
9. 访问
感谢你能够认真阅读完这篇文章,希望丸趣 TV 小编分享的“Ganglia 与 Nagios 如何整合”这篇文章对大家有帮助,同时也希望大家多多支持丸趣 TV,关注丸趣 TV 行业资讯频道,更多相关知识等着你来学习!











