共计 3334 个字符,预计需要花费 9 分钟才能阅读完成。
这篇文章将为大家详细讲解有关 prometheus13-k8s 如何部署 alertmanager,丸趣 TV 小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
1. 四个配置文件
[root@kubemaster01 alertmanager]# ls -l
-rw-r--r-- 1 root root 676 Oct 28 15:43 alertmanager-configmap.yaml
-rw-r--r-- 1 root root 2183 Oct 28 15:36 alertmanager-deployment.yaml
-rw-r--r-- 1 root root 331 Oct 28 15:36 alertmanager-pvc.yaml
-rw-r--r-- 1 root root 372 Oct 28 15:36 alertmanager-service.yaml2. 修改 pv 以及 config 的地址
[root@kubemaster01 alertmanager]# cat alertmanager-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager
namespace: kube-system
labels:
kubernetes.io/cluster-service: true
addonmanager.kubernetes.io/mode: EnsureExists
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
[root@kubemaster01 alertmanager]# cat alertmanager-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: kube-system
labels:
kubernetes.io/cluster-service: true
addonmanager.kubernetes.io/mode: EnsureExists
data:
alertmanager.yml: |
global:
resolve_timeout: 5m
smtp_smarthost: smtp.163.com:25
smtp_from: ww763004768@163.com
smtp_auth_username: ww763004768@163.com
smtp_auth_password: 123456
smtp_require_tls: false
receivers:
- name: default-receiver
email_configs:
- to: w673004768@163.com
route:
group_interval: 1m
group_wait: 10s
receiver: default-receiver
repeat_interval: 1m
[root@kubemaster01 alertmanager]#3. 部署
kubectl apply -f alertmanager-configmap.yaml
kubectl apply -f alertmanager-pvc.yaml
kubectl apply -f alertmanager-deployment.yaml
kubectl apply -f alertmanager-service.yaml4.Prometheus 和 alertmanager 通讯配置
修改 prometheus 的配置 config-map 然后从新运用
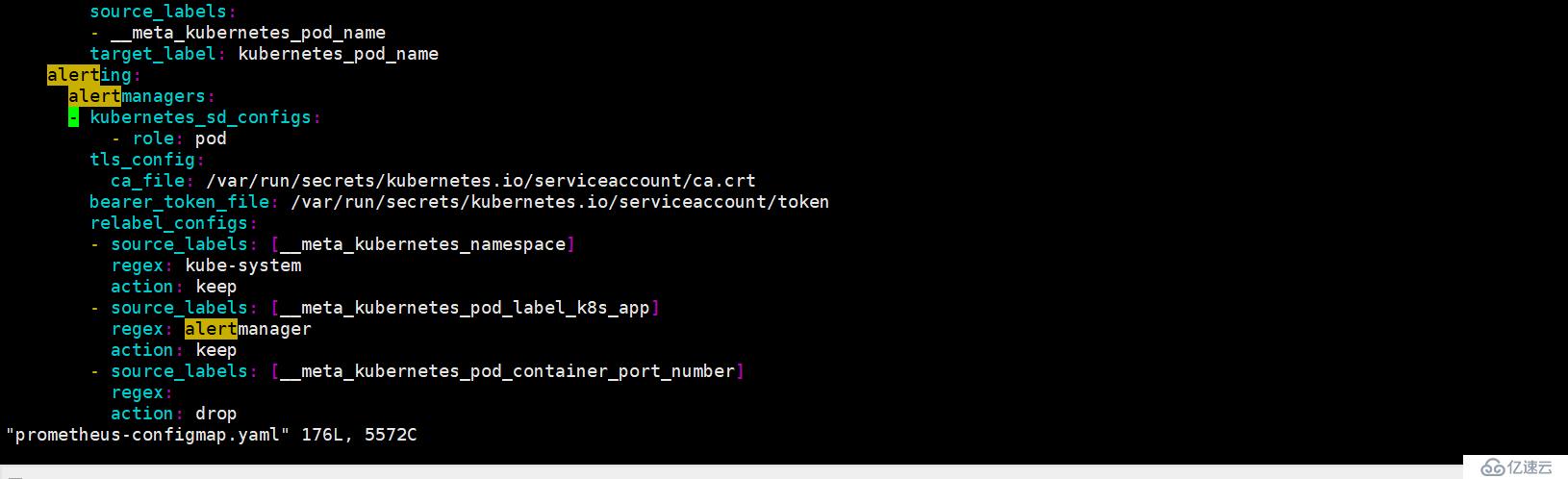
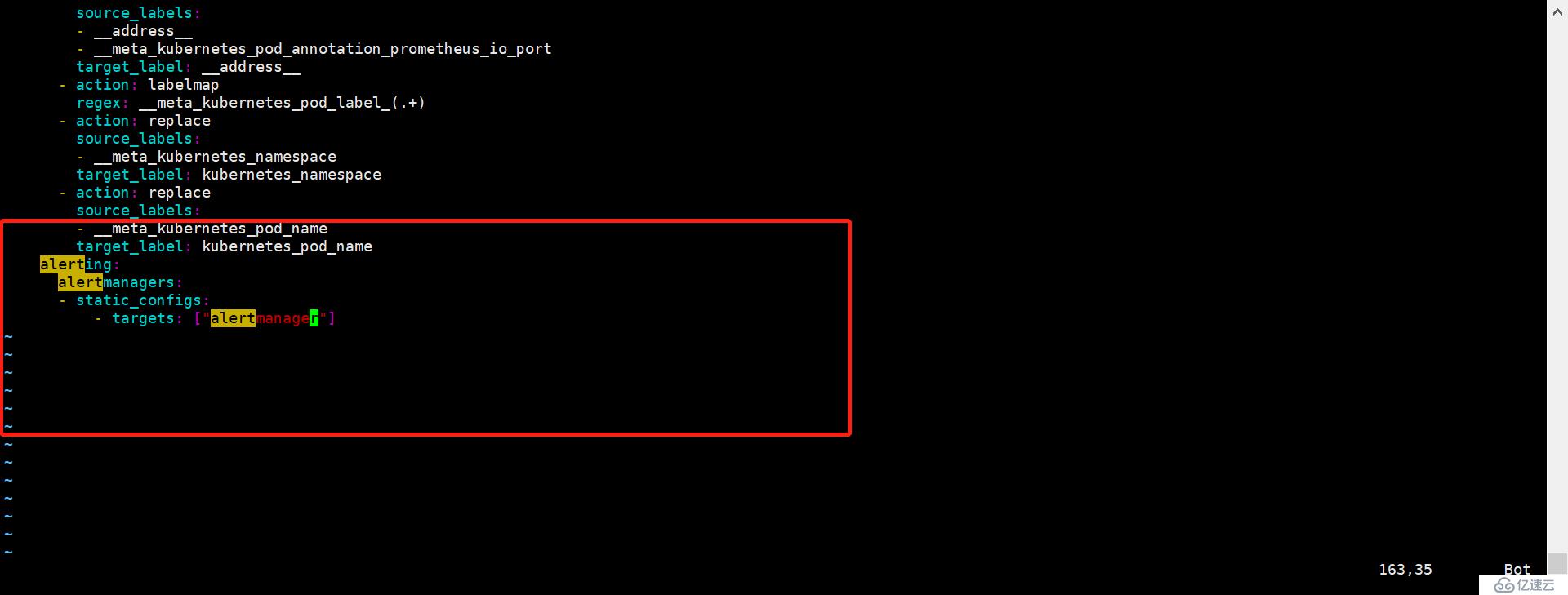
5. 查看是否生效
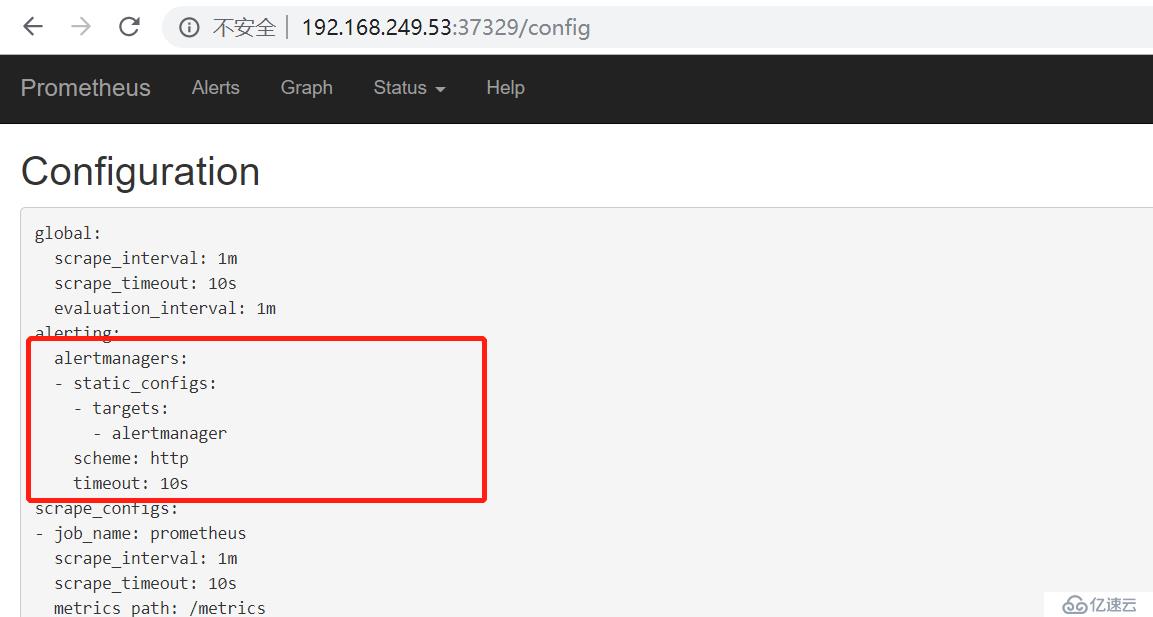
6. 修改 configmap 修改 prometheus 的报警规则的
(kubectl apply -f prometheus-configmap.yaml)

创建 configmap
kubectl apply -f prometheus-rules.yaml
[root@kubemaster01 prometheus]# cat prometheus-rules.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: kube-system
data:
general.rules: |
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: error
annotations:
summary: Instance {{ $labels.instance }} 停止工作
description: {{ $labels.instance }} job {{ $labels.job }} 已经停止 5 分钟以上.
node.rules: |
groups:
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~ ext4|xfs} / node_filesystem_size_bytes{fstype=~ ext4|xfs} * 100) 80
for: 1m
labels:
severity: warning
annotations:
summary: Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高
description: {{ $labels.instance }}: {{ $labels.mountpoint }} 分区使用大于 80% (当前值: {{ $value }})
- alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 80
for: 1m
labels:
severity: warning
annotations:
summary: Instance {{ $labels.instance }} 内存使用率过高
description: {{ $labels.instance }} 内存使用大于 80% (当前值: {{ $value }})
- alert: NodeCPUUsage
expr: 100 - (avg(irate(node_cpu_seconds_total{mode= idle}[5m])) by (instance) * 100) 60
for: 1m
labels:
severity: warning
annotations:
summary: Instance {{ $labels.instance }} CPU 使用率过高
description: {{ $labels.instance }}CPU 使用大于 60% (当前值: {{ $value }})
[root@kubemaster01 prometheus]#
prometheus 服务挂载 configmap

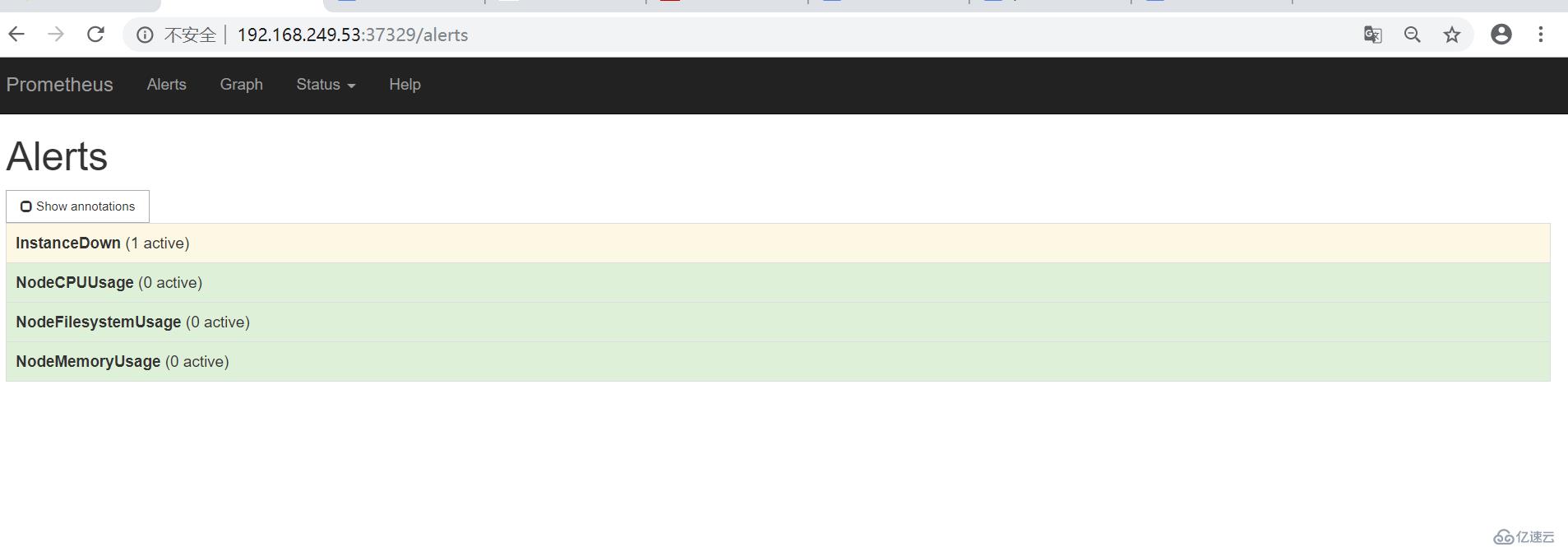

关于“prometheus13-k8s 如何部署 alertmanager”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
正文完











