共计 3316 个字符,预计需要花费 9 分钟才能阅读完成。
如何实现 Kubernetes 可观察性监测,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
我们将向您展示如何完成基本的 Kubernetes 可观察性任务: 从运行在 Kubernetes 集群上的应用程序获得黄金指标或黄金信号。我们不需要修改任何代码,也不需要进行任何配置,只要安装 Linkerd(一个开源的超轻服务网格) 就可以做到这一点。我们将介绍什么是服务网格,术语可观察性是什么意思,以及这两者在 Kubernetes 上下文中是如何关联的。
用服务网格监控 Kubernetes 应用程序
如果你们刚刚适应了 Kubernetes。恭喜你! 但是现在你需要干什么? 任何 Kubernetes 使用者者的第一个可观察性任务之一是监视,您需要知道什么时候出现了问题,以便您可以快速地修复它们。
Kubernetes 可观察性是一个非常广泛的话题,网上有很多关于可观察性与监控、分布式跟踪与日志记录等之间的细微差别的讨论。在本文中,我们将重点讨论一个基本问题: 在不更改任何代码的情况下,从运行在集群上的应用程序获得黄金指标或黄金信号。我们将安装一个 Linkerd,一个开源的超轻量级服务网格。与大多数服务网格不同,Linkerd 只需要在集群上安装几分钟,不需要配置。
虽然简单,但 Linkerd 包含了一个非常强大的度量管道。一旦安装完毕,它将通过观察集群上运行的所有组件之间的 HTTP(或 gRPC) 和 TCP 通信,自动检测并报告成功率、流量级别和响应延迟。
linkd 可以自动为服务报告度量标准通常被引用为服务的黄金度量标准。
什么是黄金度量标准? 为什么它们很重要?
如果您已经知道黄金参数是什么,请跳过这一节!
黄金指标或黄金信号是您需要了解应用程序是否按预期启动和运行的首要指标。这些度量为您提供了有关服务运行状况的粗略信号,而不需要知道服务的实际功能。
Cindy Sridharan 在她的关于监控和可观察性的博文中写道: 当不直接驱动报警时,监控数据应该被优化,以提供系统整体健康状况的鸟瞰图。
谷歌 SRE 书定义的黄金指标为:
延迟——一种衡量服务速度快慢的方法。它是服务请求所花费的时间,通常以百分比来度量。第 99 百分位延迟为 5ms 意味着 99% 的请求在 5ms 或更短的时间内得到服务。流量——让你知道某项服务有多忙或需求有多复杂。通常用每秒对服务的请求数来衡量。错误 - 请求失败的数量。通常与总流量相结合来生成一个成功率——成功请求与遇到错误请求的比率。饱和 - 衡量你的系统的负载
通过观察服务的流量,Linkerd 可以简单地提供延迟、流量和错误的测量——乐观地说,Linkerd 以成功率的形式提供了这些数据。(第四个指标,饱和度,在监控讨论中经常被忽略,因为它需要了解服务的内部情况,通常跟踪其他指标,如流量和延迟。)
有时这些指标也被称为服务的 RED 指标:
Rate——您的服务每秒正在处理的请求数。Errors—每秒失败的请求数。Duration——每个请求所花费时间的分布
不管你怎么称呼它们,Linkerd 的美妙之处在于,它不仅记录这些指标的流量,而且汇总和报告它们,这样我们就可以轻松地使用它们。(我们将在下面看到。) 这使我们能够监控我们的应用程序。一旦我们能够监控我们的应用程序,我们就可以在出错时收到报警; 研究其长期性能; 并对其可靠性和性能进行测试和改进。
黄金指标: 最简单的方法 安装: 访问 Kubernetes 集群并安装 Linkerd CLI
我们假设您有一个正常运行的 Kubernetes 集群和一个指向它的 kubectl 命令。在本节中,我们将带您浏览 linkd 入门指南的缩写版本,以便在这个集群上安装 Linkerd 和一个演示应用程序 (我们将获得最佳指标的应用程序)。
首先,安装 Linkerd 命令行 (或者,直接从 Linkerd release 页面下载。):
curl -sL https://run.linkerd.io/install | sh
export PATH=$PATH:$HOME/.linkerd2/bin
验证 Kubernetes 集群是否能够处理 linkd; 安装 Linkerd; 并验证安装:
linkerd check --pre
linkerd install | kubectl apply -f -
linkerd check
最后,安装 Emojivoto 演示应用程序,这是我们希望获得黄金指标的应用程序。如果仔细观察下面的命令,您将看到我们实际上是在向应用程序添加 linkerd(我们称之为注入),然后将应用程序部署到 Kubernetes。(如果您想知道这是如何工作的,请查看我们的文档 https://linkerd.io/2/tasks/adding-your-service/)。
curl -sL https://run.linkerd.io/emojivoto.yml \
| linkerd inject - \
| kubectl apply -f -
嗯,就是这样。这就是您需要的所有工具,您的应用程序,并能够访问您的黄金指标! 现在让我们来看看他们。
在 Grafana 查看度量
想要看到所有这些有用的图表和仪表板吗? 没有问题! 运行 linkd dashboard -show grafana 并打开命令输出的链接。您将看到 Linkerd 的顶层仪表盘,其中包含它所收集的指标的总体和每个名称空间的细分。向下滚动到我们应用程序的命名空间 (ns/emojivoto),观察以下图表:
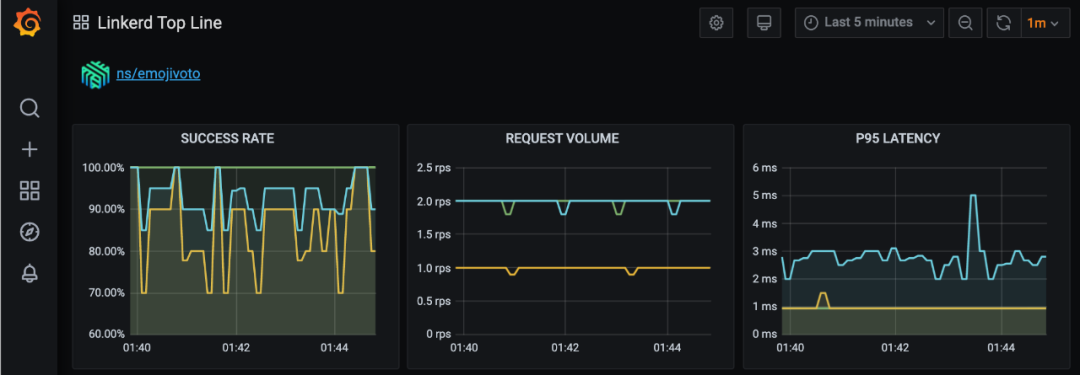
通过 linkd CLI 查看指标
我们还可以使用 linkd stat 命令查看应用程序的指标。
所有这些数据也可以在 Linkerd s dashboard 中找到,你可以通过运行 Linkerd dashboard 来访问:


看看 Grafana 图表 (或 linkd 仪表盘),你可以立即看到 voting 服务做得不是很好 - 它的成功率相当低! 向我们的应用程序中添加黄金指标可以立即让我们看到应用程序中可能出现的问题。
真的这么简单吗? 答案是肯定的! 我们所需要做的就是安装 Linkerd 并将其注入到我们的应用程序中。在底层,当 linkd 被添加到一个服务时,它会自动检测与服务的 pod 之间的任何 HTTP 和 gRPC 调用。由于它能够解析这些协议,它可以记录这些调用的响应类和延迟,并将它们聚合在一起,在这种情况下,将它们合并到一个名为 Prometheus 的时间序列数据库的小型内部实例中。当您通过 Linkerd 的仪表板和 CLI 查看黄金指标时,Linkerd 会从这个内部的 Prometheus 实例中获取它们,在不修改应用程序代码的情况下为您提供所有这些指标。
Linkerd 还能做什么?
我们已经看到了如何使用 Linkerd 来获得黄金指标,这是获得系统可观察性的第一步,也就是说,获得复杂应用程序中正在发生的事情的高级视图。但指标只是个开始。当您继续您的监视和可观察性旅程时,您一定会遇到另外两个常用的工具: 日志和分布式链路跟踪。
分布式跟踪涉及到检测应用程序,以便测量请求在服务中花费的时间长度。当我们的应用程序使用许多相互通信的微服务时,跟踪是一个很好的工具,可以用来调试缓慢的请求,并找出哪个服务是瓶颈。Linkerd 可以帮助分布式跟踪,尽管一个服务网格在分布式跟踪方面做的不多。
类似于分布式跟踪,Linkerd 也提供了一个强大的动态请求跟踪工具 tap。tap 命令类似于用于微服务的 tcpdump: 它允许您查看发送到或来自特定服务的实时请求 (示例)。Tap 是在生产中调试 Kubernetes 服务的强大工具。
最后,应用程序日志当然是开发人员在怀疑某个特定进程不正常时首先要做的事情之一。当运行一个服务网格时,有时候查看网格内部发生了什么是很有用的。虽然 Linkerd 不能为你提供应用程序日志,但 Linkerd logs 命令提供了一种简单的方法,至少可以查看 Linkerd 内部发生了什么。
关于如何实现 Kubernetes 可观察性监测问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注丸趣 TV 行业资讯频道了解更多相关知识。











