共计 11529 个字符,预计需要花费 29 分钟才能阅读完成。
这期内容当中丸趣 TV 小编将会给大家带来有关怎么实现一个 Http 服务器,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
说到 http 协议和 http 请求,很多人都知道,但是他们真的“知道”吗? 我面试过很多求职者,一说到 http 协议,他们能滔滔不绝,然后我问他 http 协议的具体格式是啥样子的? 很多人不清楚,不清楚就不清楚吧,他甚至能将 http 协议的头扯到 html 文档头部。当我问 http GET 和 POST 请求的时候,GET 请求是什么形式一般人都可以答出来,但是 POST 请求的数据放在哪里,服务器如何识别和解析这些 POST 数据,很多人又说不清道不明了。当说到 http 服务器时,很多人离开了 apache、Nginx 这样现成的 http server 之外,自己实现一个 http 服务器无从下手,如果实际应用场景有需要使用到一些简单 http 请求时,使用 apache、Nginx 这样重量级的 http 服务器程序实在劳师动众,你可以尝试自己实现一个简单的。
上面提到的问题,如果您不能清晰地回答出来,可以阅读一下这篇文章,这篇文章在不仅介绍 http 的格式,同时带领大家从零实现一个简单的 http 服务器程序。
http 协议介绍
1. http 协议是应用层协议,一般建立在 tcp 协议的基础之上(当然你的实现非要基于 udp 也是可以的),也就是说 http 协议的数据收发是通过 tcp 协议的。
2. http 协议也分为 head 和 body 两部分,但是我们一般说的 html 中的和标记不是 http 协议的头和身体,它们都是 http 协议的 body 部分。
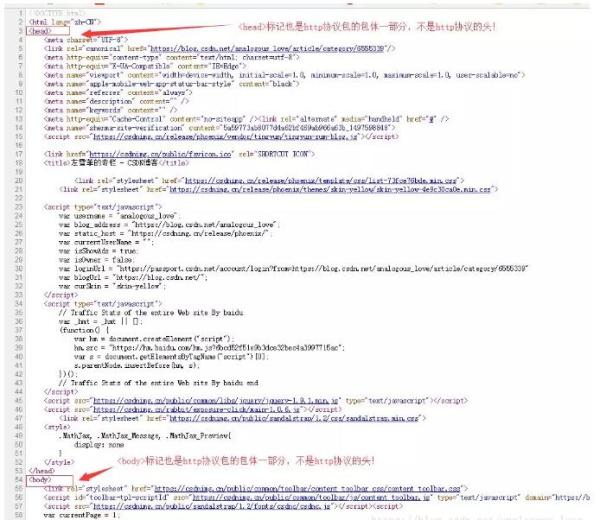
那么 http 协议的头到底长啥样子呢? 我们来介绍一下 http 协议吧。
http 协议的格式如下:
1GET 或 POST 请求的 url 路径(一般是去掉域名的路径) HTTP 协议版本号 \r\n 2 字段 1 名: 字段 1 值 \r\n 3 字段 2 名: 字段 2 值 \r\n 4 … 5 字段 n 名 : 字段 n 值 \r\n 6\r\n 7http 协议包体内容也就是说 http 协议由两部分组成:包头和包体,包头与包体之间使用一个 \r\n 分割,由于 http 协议包头的每一行都是以 \r\n 结束,所以 http 协议包头一般以 \r\n\r\n 结束。
举个例子,比如我们在浏览器中请求 http://www.hootina.org/index_2013.php 这个网址,这是一个典型的 GET 方法,浏览器组装的 http 数据包格式如下:
GET /index_2013.php HTTP/1.1\r\n 2Host: www.hootina.org\r\n 3Connection: keep-alive\r\n 4Upgrade-Insecure-Requests: 1\r\n 5User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36\r\n 6Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\n 7Accept-Encoding: gzip, deflate\r\n 8Accept-Language: zh-CN,zh;q=0.9,en;q=0.8\r\n 9\r\n上面这个请求只有包头没有包体,http 协议的包体不是必须的,也就是说 GET 请求一般没有包体。
如果 GET 请求带参数,那么一般是附加在请求的 url 后面,参数与参数之间使用 分割,例如请求 http://www.hootina.org/index_2013.php?param1=value1¶m2=value2¶m3=value3,我们看下这个请求组装的的 http 协议包格式:
GET /index_2013.php?param1=value1 param2=value2 param3=value3 HTTP/1.1\r\n 2Host: www.hootina.org\r\n 3Connection: keep-alive\r\n 4Upgrade-Insecure-Requests: 1\r\n 5User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36\r\n 6Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\n 7Accept-Encoding: gzip, deflate\r\n 8Accept-Language: zh-CN,zh;q=0.9,en;q=0.8\r\n 9\r\n对比一下,你现在知道 http 协议的 GET 参数放在协议包的什么位置了吧。
那么 POST 的数据放在什么位置呢? 我们再 12306 网站 https://kyfw.12306.cn/otn/login/init 中登陆输入用户名和密码:
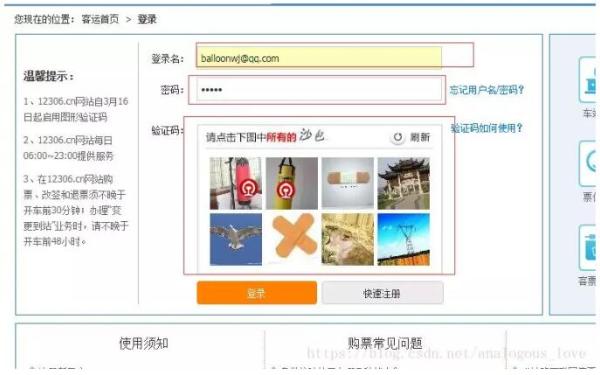
然后发现浏览器以 POST 方式组装了 http 协议包发送了我们的用户名、密码和其他一些信息,组装的包格式如下:
POST /passport/web/login HTTP/1.1\r\n 2Host: kyfw.12306.cn\r\n 3Connection: keep-alive\r\n 4Content-Length: 55\r\n 5Accept: application/json, text/javascript, */*; q=0.01\r\n 6Origin: https://kyfw.12306.cn\r\n 7X-Requested-With: XMLHttpRequest\r\n 8User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36\r\n 9Content-Type: application/x-www-form-urlencoded; charset=UTF-8\r\n 10Referer: https://kyfw.12306.cn/otn/login/init\r\n 11Accept-Encoding: gzip, deflate, br\r\n 12Accept-Language: zh-CN,zh;q=0.9,en;q=0.8\r\n 13Cookie: _passport_session=0b2cc5b86eb74bcc976bfa9dfef3e8a20712; _passport_ct=18d19b0930954d76b8057c732ce4cdcat8137; route=6f50b51faa11b987e576cdb301e545c4; RAIL_EXPIRATION=1526718782244; RAIL_DEVICEID=QuRAhOyIWv9lwWEhkq03x5Yl_livKZxx7gW6_-52oTZQda1c4zmVWxdw5Zk79xSDFHe9LJ57F8luYOFp_yahxDXQAOmEV8U1VgXavacuM2UPCFy3knfn42yTsJM3EYOy-hwpsP-jTb2OXevJj5acf40XsvsPDcM7; BIGipServerpool_passport=300745226.50215.0000; BIGipServerotn=1257243146.38945.0000; BIGipServerpassport=1005060362.50215.0000\r\n 14\r\n 15username=balloonwj%40qq.com password=iloveyou appid=otn其中 username=balloonwj%40qq.com password=iloveyou appid=otn 就是我们的 POST 数据,但是大家需要注意的以下几种,不要搞错:
1. 我的用户名是 balloonwj@qq.com,到 POST 里面变成 balloonwj%40qq.com,其中 %40 是 @符号的 16 进制转码形式。这个码表可以参考这里:http://www.w3school.com.cn/tags/html_ref_urlencode.html
2. 这里有三个变量,分别是 username、password 和 appid,他们之间使用 符号分割,但是请注意的是,这不意味着传递多个 POST 变量时必须使用 符号分割,只不过这里是浏览器 html 表单 (输入用户名和密码的文本框是 html 表单的一种) 分割多个变量采用的默认方式而已。你可以根据你的需求,来自由定制,只要让服务器知道你的解析方式即可。比如可以这么分割:
方法一
username=balloonwj%40qq.com|password=iloveyou|appid=otn方法二
username:balloonwj%40qq.com\r\n 2password:iloveyou\r\n 3appid:otn\r\n方法三
username,password,appid=balloonwj%40qq.com,iloveyou,otn不管怎么分割,只要你能自己按一定的规则解析出来就可以了。
不知道你注意到没有,上面的 POST 数据放在 http 包体中,服务器如何解析呢? 可能你没明白我的意思,看下图:
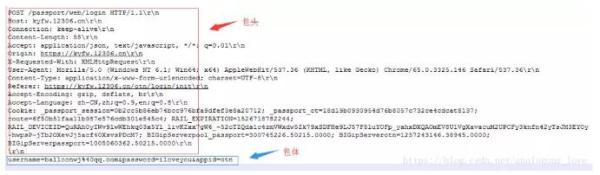
如上图所示,由于 http 协议是基于 tcp 协议的,tcp 协议是流式协议,包头部分可以通过多出的 \r\n 来分界,包体部分如何分界呢? 这是协议本身要解决的问题。目前一般有两种方式,第一种方式就是在包头中有个 content-Length 字段,这个字段的值的大小标识了 POST 数据的长度,上图中 55 就是数据 username=balloonwj%40qq.com password=iloveyou appid=otn 的长度,服务器收到一个数据包后,先从包头解析出这个字段的值,再根据这个值去读取相应长度的作为 http 协议的包体数据。还有一个格式叫做 http chunked 技术(分块),大致意思是将大包分成小包,具体的详情有兴趣的读者可以自行搜索学习。
http 客户端实现
如果您能掌握以上说的 http 协议,你就可以自己通过代码组装 http 协议发送 http 请求了 (也是各种开源 http 库的做法)。我们先简单地介绍一下如何模拟发送 http。举个例子,我们要请求 http://www.hootina.org/index_2013.php,那么我们可以先通过域名得到 ip 地址,即通过 socket API gethostbyname() 得到 www.hootina.org 的 ip 地址,由于 http 服务器默认的端口号是 80,有了域名和 ip 地址之后,我们使用 socket API connect()去连接服务器,然后根据上面介绍的格式组装成 http 协议包,利用 socket API send()函数发出去,如果服务器有应答,我们可以使用 socket API recv()去接受数据,接下来就是解析数据(先解析包头和包体)。
http 服务器实现
我们这里简化一些问题,假设客户端发送的请求都是 GET 请求,当客户端发来 http 请求之后,我们拿到 http 包后就做相应的处理。我们以为我们的 flamingo 服务器实现一个支持 http 格式的注册请求为例。假设用户在浏览器里面输入以下网址,就可以实现一个注册功能:
http://120.55.94.78:12345/register.do?p={username : 13917043329 , nickname : balloon , password : 123}
这里我们的 http 协议使用的是 12345 端口号而不是默认的 80 端口。如何侦听 12345 端口,这个是非常基础的知识了,这里就不介绍了。当我们收到数据以后:
1void HttpSession::OnRead(const std::shared_ptr TcpConnection conn, Buffer* pBuffer, Timestamp receivTime) 2{ 3 //LOG_INFO Recv a http request from conn- peerAddress().toIpPort(); 4 5 string inbuf; 6 // 先把所有数据都取出来 7 inbuf.append(pBuffer- peek(), pBuffer- readableBytes()); 8 // 因为一个 http 包头的数据至少 \r\n\r\n,所以大于 4 个字符 9 // 小于等于 4 个字符,说明数据未收完,退出,等待网络底层接着收取 10 if (inbuf.length() = 4) 11 return; 12 13 // 我们收到的 GET 请求数据包一般格式如下: 14 /* 15 GET /register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22} HTTP/1.1\r\n 16 Host: 120.55.94.78:12345\r\n 17 Connection: keep-alive\r\n 18 Upgrade-Insecure-Requests: 1\r\n 19 User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36\r\n 20 Accept-Encoding: gzip, deflate\r\n 21 Accept-Language: zh-CN, zh; q=0.9, en; q=0.8\r\n 22 \r\n 23 */ 24 // 检查是否以 \r\n\r\n 结束,如果不是说明包头不完整,退出 25 string end = inbuf.substr(inbuf.length() - 4); 26 if (end != \r\n\r\n) 27 return; 28 29 // 以 \r\n 分割每一行 30 std::vector string lines; 31 StringUtil::Split(inbuf, lines, \r\n 32 if (lines.size() 1 || lines[0].empty()) 33 { 34 conn- forceClose(); 35 return; 36 } 37 38 std::vector string chunk; 39 StringUtil::Split(lines[0], chunk, 40 //chunk 中至少有三个字符串:GET+url+HTTP 版本号 41 if (chunk.size() 3) 42 { 43 conn- forceClose(); 44 return; 45 } 46 47 LOG_INFO url: chunk[1] from conn- peerAddress().toIpPort(); 48 //inbuf = /register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22} 49 std::vector string part; 50 // 通过? 分割成前后两端,前面是 url,后面是参数 51 StringUtil::Split(chunk[1], part, ? 52 //chunk 中至少有三个字符串:GET+url+HTTP 版本号 53 if (part.size() 2) 54 { 55 conn- forceClose(); 56 return; 57 } 58 59 string url = part[0]; 60 string param = part[1].substr(2); 61 62 if (!Process(conn, url, param)) 63 { 64 LOG_ERROR handle http request error, from: conn- peerAddress().toIpPort() , request: pBuffer- retrieveAllAsString(); 65 } 66 67 // 短连接,处理完关闭连接 68 conn- forceClose(); 69}代码注释都写的很清楚,我们先利用 \r\n 分割得到每一行,其中第一行的数据是:
GET /register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22} HTTP/1.1其中 %22 是双引号的 url 转码形式,%20 是空格的 url 转码形式,然后我们根据空格分成三段,其中第二段就是我们的网址和参数:
/register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22}然后我们根据网址与参数之间的问号将这个分成两段:第一段是网址,第二段是参数:
1bool HttpSession::Process(const std::shared_ptr TcpConnection conn, const std::string url, const std::string param) 2{ 3 if (url.empty()) 4 return false; 5 6 if (url == /register.do) 7 { 8 OnRegisterResponse(param, conn); 9 } 10 else if (url == /login.do) 11 { 12 OnLoginResponse(param, conn); 13 } 14 else if (url == /getfriendlist.do) 15 { 16 17 } 18 else if (url == /getgroupmembers.do) 19 { 20 21 } 22 else 23 return false; 24 25 26 return true; 27}然后我们根据 url 匹配网址,如果是注册请求,会走注册处理逻辑:
void HttpSession::OnRegisterResponse(const std::string data, const std::shared_ptr TcpConnection conn) 2{ 3 string retData; 4 string decodeData; 5 URLEncodeUtil::Decode(data, decodeData); 6 BussinessLogic::RegisterUser(decodeData, conn, false, retData); 7 if (!retData.empty()) 8 { 9 std::string response; 10 URLEncodeUtil::Encode(retData, response); 11 MakeupResponse(retData, response); 12 conn- send(response); 13 14 LOG_INFO Response to client: cmd=msg_type_register , data= retData conn- peerAddress().toIpPort();; 15 } 16}注册结果放在 retData 中,为了发给客户端,我们将结果中的特殊字符如双引号转码,如返回结果是:
{code :0, msg : ok}会被转码成:
{%22code%22:0,%20%22msg%22:%22ok%22}然后,将数据组装成 http 协议发给客户端,给客户端的应答协议与 http 请求协议有一点点差别,就是将请求的 url 路径换成所谓的 http 响应码,如 200 表示应答正常返回、404 页面不存在。应答协议格式如下:
GET 或 POST 响应码 HTTP 协议版本号 \r\n 2 字段 1 名: 字段 1 值 \r\n 3 字段 2 名: 字段 2 值 \r\n 4 … 5 字段 n 名 : 字段 n 值 \r\n 6\r\n 7http 协议包体内容举个例子如:
HTTP/1.1 200 OK\r\n Content-Type: text/html\r\n Content-Length:42\r\n \r\n {%22code%22:%200,%20%22msg%22:%20%22ok%22}注意,包头中的 Content-Length 长度必须正好是包体 {%22code%22:%200,%20%22msg%22:%20%22ok%22} 的长度,这里是 42。这也符合我们浏览器的返回结果:

当然,需要注意的是,我们一般说 http 连接一般是短连接,这里我们也实现了这个功能(看上面的代码:conn- forceClose();),不管一个 http 请求是否成功,服务器处理后立马就关闭连接。
当然,这里还有一些没处理好的地方,如果你仔细观察上面的代码就会发现这个问题,就是不满足一个 http 包头时的处理,如果某个客户端 (不是使用浏览器) 通过程序模拟了一个连接请求,但是迟迟不发含有 \r\n\r\n 的数据,这路连接将会一直占用。我们可以判断收到的数据长度,防止别有用心的客户端给我们的服务器乱发数据。我们假定,我们能处理的最大 url 长度是 2048,如果用户发送的数据累积不含 \r\n\r\n,且超过 2048 个,我们认为连接非法,将连接断开。代码修改成如下形式:
void HttpSession::OnRead(const std::shared_ptr TcpConnection conn, Buffer* pBuffer, Timestamp receivTime) { //LOG_INFO Recv a http request from conn- peerAddress().toIpPort(); string inbuf; // 先把所有数据都取出来 inbuf.append(pBuffer- peek(), pBuffer- readableBytes()); // 因为一个 http 包头的数据至少 \r\n\r\n,所以大于 4 个字符 // 小于等于 4 个字符,说明数据未收完,退出,等待网络底层接着收取 if (inbuf.length() = 4) return; // 我们收到的 GET 请求数据包一般格式如下: /* GET /register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22} HTTP/1.1\r\n Host: 120.55.94.78:12345\r\n Connection: keep-alive\r\n Upgrade-Insecure-Requests: 1\r\n User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36\r\n Accept-Encoding: gzip, deflate\r\n Accept-Language: zh-CN, zh; q=0.9, en; q=0.8\r\n \r\n */ // 检查是否以 \r\n\r\n 结束,如果不是说明包头不完整,退出 string end = inbuf.substr(inbuf.length() - 4); if (end != \r\n\r\n) return; // 超过 2048 个字符,且不含 \r\n\r\n,我们认为是非法请求 else if (inbuf.length() = MAX_URL_LENGTH) { conn- forceClose(); return; } // 以 \r\n 分割每一行 std::vector string lines; StringUtil::Split(inbuf, lines, \r\n if (lines.size() 1 || lines[0].empty()) { conn- forceClose(); return; } std::vector string chunk; StringUtil::Split(lines[0], chunk, //chunk 中至少有三个字符串:GET+url+HTTP 版本号 if (chunk.size() 3) { conn- forceClose(); return; } LOG_INFO url: chunk[1] from conn- peerAddress().toIpPort(); //inbuf = /register.do?p={%22username%22:%20%2213917043329%22,%20%22nickname%22:%20%22balloon%22,%20%22password%22:%20%22123%22} std::vector string part; // 通过? 分割成前后两端,前面是 url,后面是参数 StringUtil::Split(chunk[1], part, ? //chunk 中至少有三个字符串:GET+url+HTTP 版本号 if (part.size() 2) { conn- forceClose(); return; } string url = part[0]; string param = part[1].substr(2); if (!Process(conn, url, param)) { LOG_ERROR handle http request error, from: conn- peerAddress().toIpPort() , request: pBuffer- retrieveAllAsString(); } // 短连接,处理完关闭连接 conn- forceClose(); }
但这只能解决发送非法数据的情况,如果一个客户端连上来不给我们发任何数据,这段逻辑就无能为力了。如果不断有客户端这么做,会浪费我们大量的连接资源,所以我们还需要一个定时器去定时检测哪些 http 连接超过一定时间内没给我们发数据,找到后将连接断开。
上述就是丸趣 TV 小编为大家分享的怎么实现一个 Http 服务器了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注丸趣 TV 行业资讯频道。











