共计 9891 个字符,预计需要花费 25 分钟才能阅读完成。
如何设计并实现存储 QoS,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面丸趣 TV 小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
1. 资源抢占问题
随着存储架构的调整,众多应用服务会运行在同一资源池中,对外提供统一的存储能力。资源池内部可能存在多种流量类型,如上层业务的 IO 流量、存储内部的数据迁移、修复、压缩等,不同的流量通过竞争的方式确定下发到硬件的 IO 顺序,因此无法确保某种流量 IO 服务质量,比如内部数据迁移流量可能占用过多的带宽影响业务流量读写,导致存储对外提供的服务质量下降,由于资源竞争结果的不确定性无法保障存储对外能提供稳定的集群环境。
如下面交通图所示,车辆逆行、加塞随心随遇,行人横穿、闲聊肆无忌惮,最终出现交通拥堵甚至安全事故。
2. 如何解决资源抢占
类比上一幅交通图,如何规避这样的现象大家可能都有自己的一些看法,这里先引入两个名词
QoS,即服务质量,根据不同服务类型的不同需求提供端到端的服务质量。
存储 QoS,在保障服务带宽与 IOPS 的情况下,合理分配存储资源,有效缓解或控制应用服务对资源的抢占,实现流量监控、资源合理分配、重要服务质量保证以及内部流量规避等效果,是存储领域必不可少的一项关键技术。
那么 QoS 应该怎么去做呢?下面还是结合交通的例子进行介绍说明。
2.1 流量分类
从前面的图我们看到不管是什么车,都以自我为中心,不受任何约束,我们首先能先到的办法是对道路进行分类划分,比如分为公交车专用车道、小型车专用车道、大货车专用车道、非机动车道以及人行横道等,正常情况下公交车车道只允许公交车运行,而非机动车道上是不允许出现机动车的,这样我们可以保证车道与车道之间不受制约干扰。
同样,存储内部也会有很多流量,我们可以为不同的流量类型分配不同的“车道”,比如业务流量的车道我们划分宽一些,而内部压缩流量的车道相对来说可以窄一些,由此引入了 QoS 中一个比较重要的概览就是流量分类,根据分类结果可以进行更加精准个性化的限流控制。
2.2 流量优先级
仅仅依靠分类是不行的,因为总有一些特殊情况,比如急救车救人、警车抓人等,我们总不能说这个车道只能跑普通私家小轿车把,一些特殊车辆(救护车,消防车以及警车等)应该具有优先通行的权限。

对于存储来说业务流量就是我们的特殊车辆,我们需要保证业务流量的稳定性,比如业务流量的带宽跟 IOPS 不受限制,而内部流量如迁移、修复则需要限定其带宽或者 IOPS,为其分配固定的“车道”。在资源充足的情况下,内部流量可以安安静静的在自己的车道上行驶,但是当资源紧张,比如业务流量突增或者持续性的高流量水位,这个时候需要限制内部流量的道理宽度,极端情况下可以暂停。当然,如果内部流量都停了还是不能满足正常业务流量的读写需求,这个时候就需要考虑扩容的事情了。
QoS 中另外一个比较重要的概念就是优先级划分,在资源充足的情况下执行预分配资源策略,当资源紧张时对优先级低的服务资源进行动态调整,进行适当的规避或者暂停,在一定程度上可以弥补预分配方案的不足。
2.3 流量监控
前面提到当资源不足时,我们可以动态的去调整其他流量的阈值,那我们如何知道资源不足呢?这个时候我们是需要有个流量监控的组件。
我们出行时经常会使用地图,通过选择合适的线路以最快到达目的地。一般线路会通过不同的颜色标记线路拥堵情况,比如红色表示堵车、绿色表示畅通。
存储想要知道机器或者磁盘当前的流量情况有两种方式:
统计机器负载情况,比如我们经常去机器上通过 iostat 命名查看各个磁盘的 io 情况,这种方式与机器上的应用解耦,只关注机器本身
统计各个应用下发的读写流量,比如某台机器上部署了一个存储节点应用,那我们可以统计这个应用下发下去的读写带宽及 IOPS
第二种方式相对第一种可以实现应用内部更细的流量分类,比如前面提到的一个存储应用节点,就包含了多种流量,我们不能通过机器的粒度对所有流量统一限流。
3. 常见 QoS 限流算法 3.1 固定窗口算法
按时间划分为多个限流窗口,比如 1 秒为一个限流窗口大小;
每个窗口都有一个计数器,每通过一个请求计数器会加一;
当计数器大小超过了限制大小(比如一秒内只能通过 100 个请求),则窗口内的其他请求会被丢弃或排队等待,等到下一个时间节点计数器清零再处理请求。
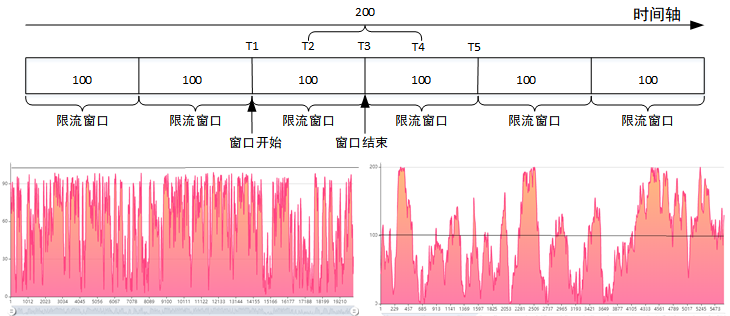
固定窗口算法的理想流量控制效果如上左侧图所示,假定设置 1 秒内允许的最大请求数为 100,那么 1 秒内的最大请求数不会超过 100。
但是大多数情况下我们会得到右侧的曲线图,即可能会出现流量翻倍的效果。比如前 T1~T2 时间段没有请求,T2~T3 来了 100 个请求,全部通过。下一个限流窗口计数器清零,然后 T3T4 时间内来了 100 个请求,全部处理成功,这个时候时间段 T4T5 时间段就算有请求也是不能处理的,因此超过了设定阈值,最终 T2~T4 这一秒时间处理的请求为 200 个,所以流量翻倍。
小结
算法易于理解,实现简单;
流量控制不够精细,容易出现流量翻倍情况;
适合流量平缓并允许流量翻倍的模型。
3.2 滑动窗口算法
前面提到固定窗口算法容易出现流量控制不住的情况(流量翻倍),滑动窗口可以认为是固定窗口的升级版本,可以规避固定窗口导致的流量翻倍问题。
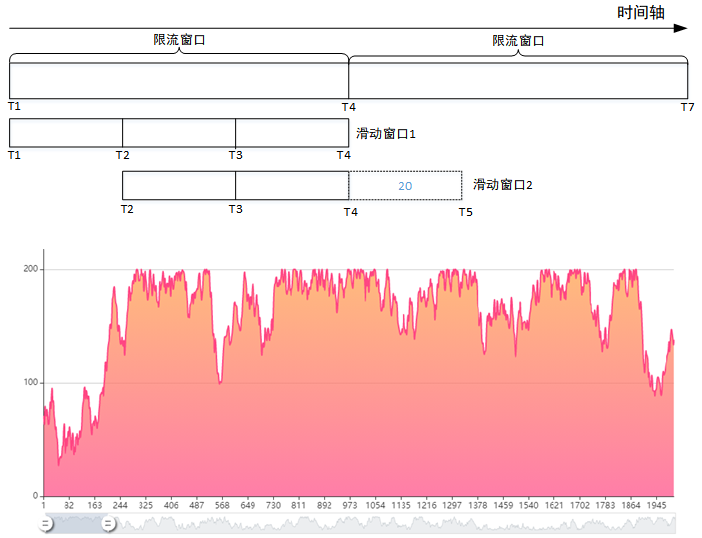
时间窗口被细分若干个小区间,比如之前一秒一个窗口(最大允许通过 60 个请求),现在一秒分成 3 个小区间,每个小区间最大允许通过 20 个请求;
每个区间都有一个独立的计数器,可以理解一个区间就是固定窗口算法中的一个限流窗口;
当一个区间的时间用完,滑动窗口往后移动一个分区,老的分区 (T1~T2) 被丢弃,新的分区 (T4~T5) 加入滑动窗口,如图所示。
小结
流量控制更加精准,解决了固定窗口算法导致的流量翻倍问题;
区间划分粒度不易确定,粒度太小会增加计算资源,粒度太大又会导致整体流量曲线不够平滑,使得系统负载忽高忽低;
适合流量较为稳定,没有大量流量突增模型。
3.3 漏斗算法
所有的水滴(请求)都会先经过“漏斗”存储起来(排队等待);
当漏斗满了之后,多余的水会被丢弃或者进入一个等待队列中;
漏斗的另外一端会以一个固定的速率将水滴排出。
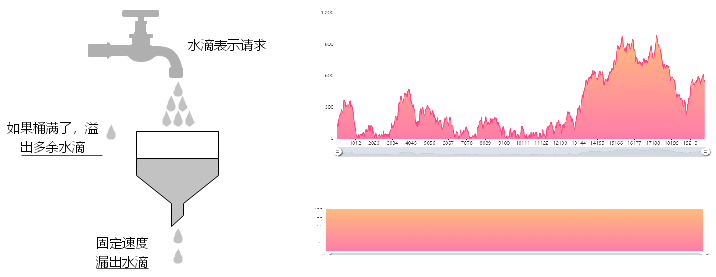
对于漏斗而言,他不清楚水滴(请求)什么时候会流入,但是总能保证出水的速度不会超过设定的阈值,请求总是以一个比较平滑的速度被处理,如图所示,系统经过漏斗算法限流之后,流量能保证在一个恒定的阈值之下。
小结
稳定的处理速度,可以达到整流的效果,主要对下游的系统起到保护作用;
无法应对流量突增情况,所有的请求经过漏斗都会被削缓,因此不适合有流量突发的限流场景;
适合没有流量突增或想达到流量整合以固定速率处理的模型。
3.4 令牌桶算法
令牌桶算法是漏斗算法的一种改进,主要解决漏斗算法不能应对流量突发的场景
以固定的速率产生令牌并投入桶中,比如一秒投放 N 个令牌;
令牌桶中的令牌数如果大于令牌桶大小 M,则多余的令牌会被丢弃;
所有请求到达时,会先从令牌桶中获取令牌,拿到令牌则执行请求,如果没有获取到令牌则请求会被丢弃或者排队等待下一次尝试获取令牌。
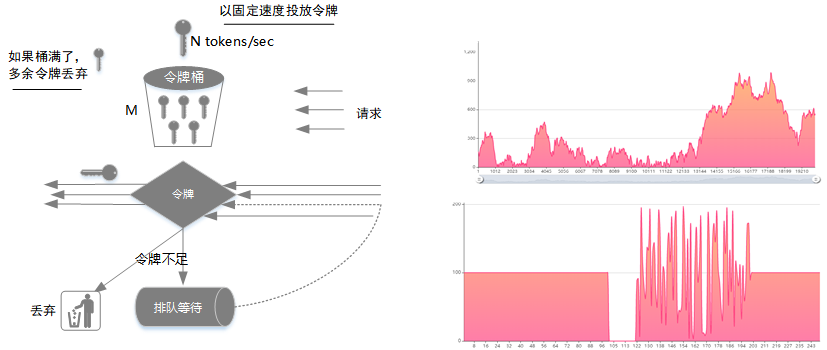
如图所示,假设令牌投放速率为 100/s,桶能存放最大令牌数 200,当请求速度大于另外投放速率时,请求会被限制在 100/s。如果某段时间没有请求,这个时候令牌桶中的令牌数会慢慢增加直到 200 个,这是请求可以一次执行 200,即允许设定阈值内的流量并发。
小结
流量平滑;
允许特定阈值内的流量并发;
适合整流并允许一定程度流量突增的模型。
就单纯的以算法而言,没有哪个算法最好或者最差的说法,需要结合实际的流量特征以及系统需求等因素选择最合适的算法。
四、存储 QoS 设计及实现 4.1 需求
一般而言一台机器会至少部署一个存储节点,节点负责多块磁盘的读写请求,而存储请求由分为多种类型,比如正常业务的读写流量、磁盘损坏的修复流量、数据删除出现数据空洞后的空间压缩流量以及多为了降低多副本存储成本的纠删码(EC)迁移流量等等,不同流量出现在同一个存储节点会相互竞争抢占系统资源,为了更好的保证业务服务质量,需要对流量的带宽以及 IOPS 进行限制管控,比如需要满足以下条件:
可以同时限制流量的带宽跟 IOPS,单独的带宽或者 IOPS 限制都会导致另外一个参数不受控制而影响系统稳定性,比如只控制了带宽,但是没有限制 IOPS,对于大量小 IO 的场景就会导致机器的 ioutil 过高;
可以实现磁盘粒度的限流,避免机器粒度限流导致磁盘流量过载,比如图所示,ec 流量限制节点的带宽最大值为 10Mbps,预期效果是想每块磁盘分配 2Mbps,但是很有可能这 10Mbps 全部分配到了第一个磁盘;
可以支持流量分类控制,根据不同的流量特性设置不同的限流参数,比如业务流量是我们需要重点保护的,因此不能对业务流量进行限流,而 EC、压缩等其他流量均为内部流量,可以根据其特性配置合适的限流阈值;
可以支持限流阈值的动态适配,由于业务流量不能进行流控,对于系统而言就像一匹“脱缰野马”,可能突增、突减或持续高峰,针对突增或持续高峰的场景系统需要尽可能的为其分配资源,这就意味着需要对内部流量的限流阈值进行动态的打压设置是暂停规避。
4.2 算法选择
前面提到了 QoS 的算法有很多,这里我们结合实际需求选择滑动窗口算法,主要有以下原因:
系统需要控制内部流量而内部流量相对比较稳定平缓;
可以避免流量突发情况而影响业务流量;
QoS 组件除了滑动窗口,还需要添加一个缓存队列,当请求被限流之后不能被丢弃,需要添加至缓存队列中,等待下一个时间窗口执行,如下图所示。
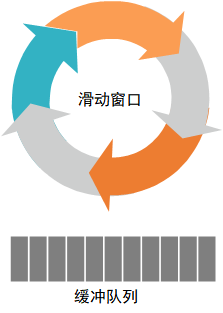
4.3 带宽与 IOPS 同时限制
为了实现带宽与 IOPS 的同时控制,QoS 组件将由两部分组成:IOPS 控制组件负责控制读写的 IOPS,带宽控制组件负责控制读写的带宽,带宽控制跟 IOPS 控制类似,比如带宽限制阈值为 1Mbps,那么表示一秒最多只能读写 1048576Bytes 大小数据;假定 IOPS 限制为 20iops,表示一秒内最多只能发送 20 次读写请求,至于每次读写请求的大小并不关心。
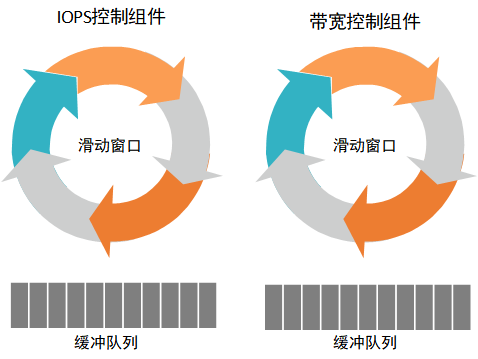
两个组件内部相互隔离,整体来看又相互影响,比如当 IOPS 控制很低时,对应的带宽可能也会较小,而当带宽控制很小时对应的 IOPS 也会比较小。
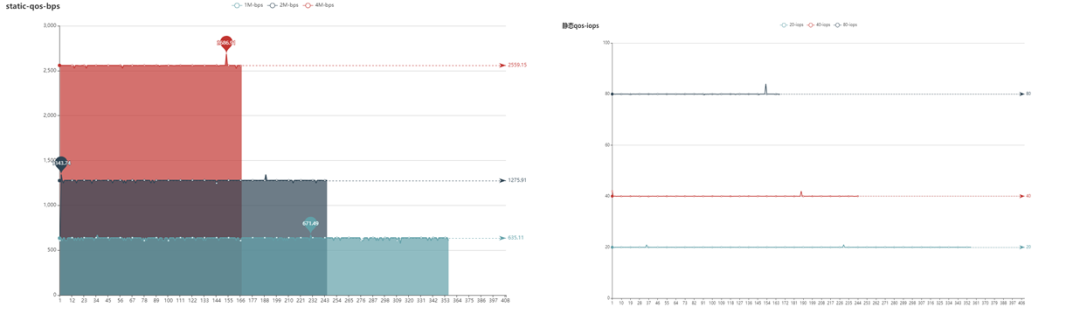
下面以修复流量为例,分三组进行测试
第一组:20iops-1Mbps
第二组:40iops-2Mbps
第三组:80iops-4Mbps
测试结果如上图所示,从图中可以看到 qos 模块能控制流量的带宽跟 iops 维持在设定阈值范围内。
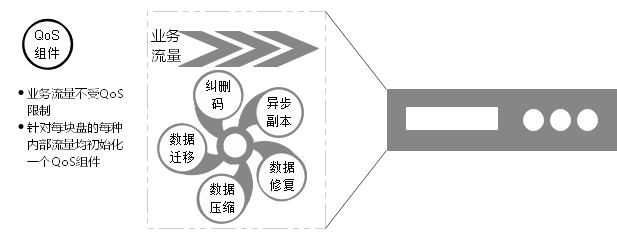
4.4 流量分类限制
为了区分不同的流量,我们对流量进行标记分类,并为不同磁盘上的不同流量都初始化一个 QoS 组件,QoS 组件之间相互独立互不影响,最终可以达到磁盘粒度的带宽跟 IOPS 控制。
4.5 动态阈值调整
前面提到的 QoS 限流方案,虽然能够很好的控制内部流量带宽或者 IOPS 在阈值范围内,但是存在以下不足
不感知业务流量现状,当业务流量突增或者持续高峰时,内部流量与业务流量仍然会存在资源抢占,不能达到流量规避或暂停效果。
磁盘上不同流量的限流相互独立,当磁盘的整体流量带宽或者 IOPS 过载时,内部流量阈值不能动态调低也会影响业务流量的服务质量。
所以需要对 QoS 组件进行一定的改进,增加流量监控组件,监控组件主要监控不同流量类型的带宽与 IOPS,动态 QoS 限流方案支持以下功能:
通过监控组件获取流量增长率,如果出现流量突增,则动态调低滑动窗口阈值以降低内部流量;当流量恢复平缓,恢复滑动窗口最初阈值以充分利用系统资源。
通过监控组件获取磁盘整体流量,当整体流量大小超过设定阈值,则动态调低滑动窗口大小;当整体流量大小低于设定阈值,则恢复滑动窗口至初始阈值。
下面设置磁盘整体流量阈值 2Mbps-40iops,ec 流量的阈值为 10Mbps-600iops
当磁盘整体流量达到磁盘阈值时会动态调整其他内部流量的阈值,从测试结果可以看到 ec 的流量受动态阈值调整存在一些波动,磁盘整体流量下去之后 ec 流量阈值又会恢复到最初阈值(10Mbps-600iops),但是可以看到整体磁盘的流量并没有控制在 2Mbps-40iops 以下,而是在这个范围上下波动,所以我们在初始化时需要保证设置的内部流量阈值小于磁盘的整体流量阈值,这样才能达到比较稳定的内部流量控制效果。

4.6 伪代码实现
前面提到存储 QoS 主要是限制读写的带宽跟 IOPS,具体应该如何去实现呢?IO 读写主要涉及以下几个接口。
Read(p []byte) (n int, err error)ReadAt(p []byte, off int64) (n int, err error)Write(p []byte) (written int, err error)WriteAt(p []byte, off int64) (written int, err error)所以这里需要对上面几个接口进行二次封装,主要是加入限流组件。
带宽控制组件实现
Read 实现
// 假定 c 为限流组件 func (self *bpsReader) Read(p []byte) (n int, err error) {
size := len(p) size = self.c.assign(size) // 申请读取文件大小
n, err = self.underlying.Read(p[:size]) // 根据申请大小读取对应大小数据 self.c.fill(size - n) // 如果读取的数据大小小于申请大小,将没有用掉的计数填充至限流窗口中 return}
Read 限流之后会出现以下情况
读取大小 n len(p)且 err=nil,比如需要读 4K 大小,但是当前时间窗口只能允许读取 3K,这个是被允许的
这里也许你会想,Read 限流的实现怎么不弄个循环呢?如直到读取指定大小数据才返回。这里的实现我们需要参考标准的 IO 的读接口定义,其中有说明在读的过程中如果准备好的数据不足 len(p)大小,这里直接返回准备好的数据,而不是等待,也就是说标准的语义是支持只读部分准备好的数据,因此这里的限流实现保持一致。
// Reader is the interface that wraps the basic Read method.//// Read reads up to len(p) bytes into p. It returns the number of bytes// read (0 = n = len(p)) and any error encountered. Even if Read// returns n len(p), it may use all of p as scratch space during the call.// If some data is available but not len(p) bytes, Read conventionally// returns what is available instead of waiting for more.// 省略 //// Implementations must not retain p.type Reader interface { Read(p []byte) (n int, err error)}ReadAt 实现
下面介绍下 ReadAt 的实现,从接口的定义来看,可能觉得 ReadAt 与 Read 相差不大,仅仅是指定了数据读取的开始位置,细心的小伙伴可能发现我们这里实现时多了一层循环,需要读到指定大小数据或者出现错误才返回,相比 Read 而言 ReadAt 是不允许出现 *n len(p)且 err==nil* 的情况。
func (self *bpsReaderAt) ReadAt(p []byte, off int64) (n int, err error) { for n len(p) err == nil { var nn int nn, err = self.readAt(p[n:], off) off += int64(nn) n += nn } return}
func (self *bpsReaderAt) readAt(p []byte, off int64) (n int, err error) { size := len(p) size = self.c.assign(size) n, err = self.underlying.ReadAt(p[:size], off) self.c.fill(size - n) return}// ReaderAt is the interface that wraps the basic ReadAt method.//// ReadAt reads len(p) bytes into p starting at offset off in the// underlying input source. It returns the number of bytes// read (0 = n = len(p)) and any error encountered.//// When ReadAt returns n len(p), it returns a non-nil error// explaining why more bytes were not returned. In this respect,// ReadAt is stricter than Read.//// Even if ReadAt returns n len(p), it may use all of p as scratch// space during the call. If some data is available but not len(p) bytes,// ReadAt blocks until either all the data is available or an error occurs.// In this respect ReadAt is different from Read.// 省略 //// Implementations must not retain p.type ReaderAt interface { ReadAt(p []byte, off int64) (n int, err error)}Write 实现
Write 接口的实现相对比较简单,循环写直到写完数据或者出现错误
func (self *bpsWriter) Write(p []byte) (written int, err error) { size := 0 for size != len(p) { p = p[size:] size = self.c.assign(len(p))
n, err := self.underlying.Write(p[:size]) self.c.fill(size - n) written += n if err != nil { return written, err } } return}// Writer is the interface that wraps the basic Write method.//// Write writes len(p) bytes from p to the underlying data stream.// It returns the number of bytes written from p (0 = n = len(p))// and any error encountered that caused the write to stop early.// Write must return a non-nil error if it returns n len(p).// Write must not modify the slice data, even temporarily.//// Implementations must not retain p.type Writer interface { Write(p []byte) (n int, err error)}WriteAt 实现
这里的实现跟 Write 类似
func (self *bpsWriterAt) WriteAt(p []byte, off int64) (written int, err error) { size := 0 for size != len(p) { p = p[size:] size = self.c.assign(len(p))
n, err := self.underlying.WriteAt(p[:size], off) self.c.fill(size - n) off += int64(n) written += n if err != nil { return written, err } } return}// WriterAt is the interface that wraps the basic WriteAt method.//// WriteAt writes len(p) bytes from p to the underlying data stream// at offset off. It returns the number of bytes written from p (0 = n = len(p))// and any error encountered that caused the write to stop early.// WriteAt must return a non-nil error if it returns n len(p).//// If WriteAt is writing to a destination with a seek offset,// WriteAt should not affect nor be affected by the underlying// seek offset.//// Clients of WriteAt can execute parallel WriteAt calls on the same// destination if the ranges do not overlap.//// Implementations must not retain p.type WriterAt interface { WriteAt(p []byte, off int64) (n int, err error)}IOPS 控制组件实现
IOPS 控制组件的实现跟带宽类似,这里就不详细介绍了
Read 接口实现
func (self *iopsReader) Read(p []byte) (n int, err error) { self.c.assign(1) // 这里只需要获取一个计数,如果当前窗口一个都没有,则会一直等待直到获取到一个才唤醒执行下一步 n, err = self.underlying.Read(p) return}ReadAt 接口实现
func (self *iopsReaderAt) ReadAt(p []byte, off int64) (n int, err error) { self.c.assign(1) n, err = self.underlying.ReadAt(p, off) return}想想这里的 ReadAt 为啥不需要跟带宽一样循环读了呢?
Write 接口实现
func (self *iopsWriter) Write(p []byte) (written int, err error) { self.c.assign(1) written, err = self.underlying.Write(p) return}WriteAt
func (self *iopsWriterAt) WriteAt(p []byte, off int64) (n int, err error) { self.c.assign(1) n, err = self.underlying.WriteAt(p, off) return}看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注丸趣 TV 行业资讯频道,感谢您对丸趣 TV 的支持。











