共计 2986 个字符,预计需要花费 8 分钟才能阅读完成。
本篇文章为大家展示了 RPC 框架 Dubbo 中非阻塞通信下的同步 API 实现原理是什么,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
Netty 在 Java NIO 领域基本算是独占鳌头,涉及到高性能网络通信,基本都会以 Netty 为底层通信框架,Dubbo 也不例外。以下将以 Dubbo 实现为例介绍其是如何在 NIO 非阻塞通信基础上实现同步通信的。
Dubbo 为一种 RPC 通信框架,提供进程间的通信,在使用 dubbo 协议 +Netty 作为传输层时,提供三种 API 调用方式:
同步接口
异步带回调接口
异步不带回调接口
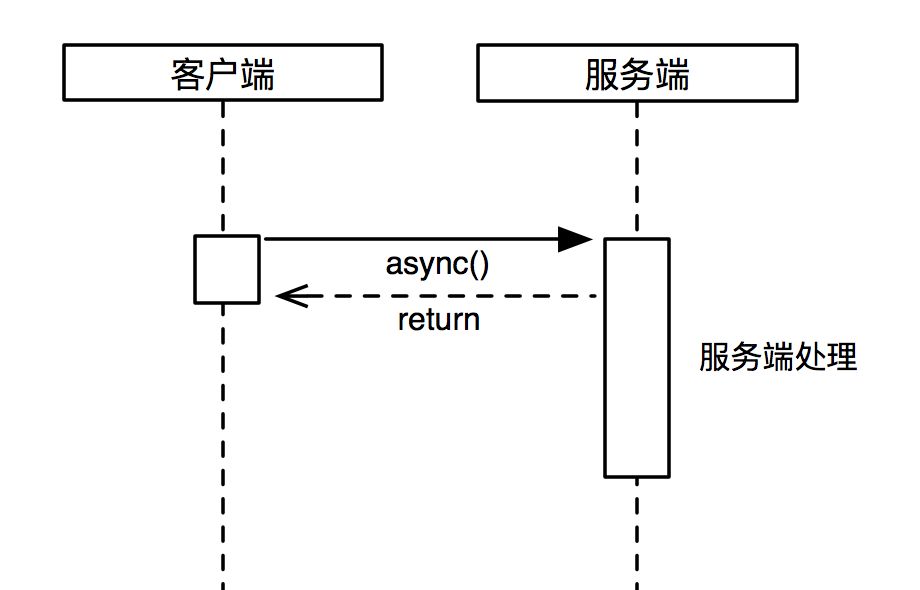
同步接口适用在大部分环境,通信方式简单、可靠,客户端发起调用,等待服务端处理,调用结果同步返回。这种方式下,在高吞吐、高性能(响应时间很快)的服务接口场景中最为适用,可以减少异步带来的额外的消耗,也方便客户端做一致性保证。
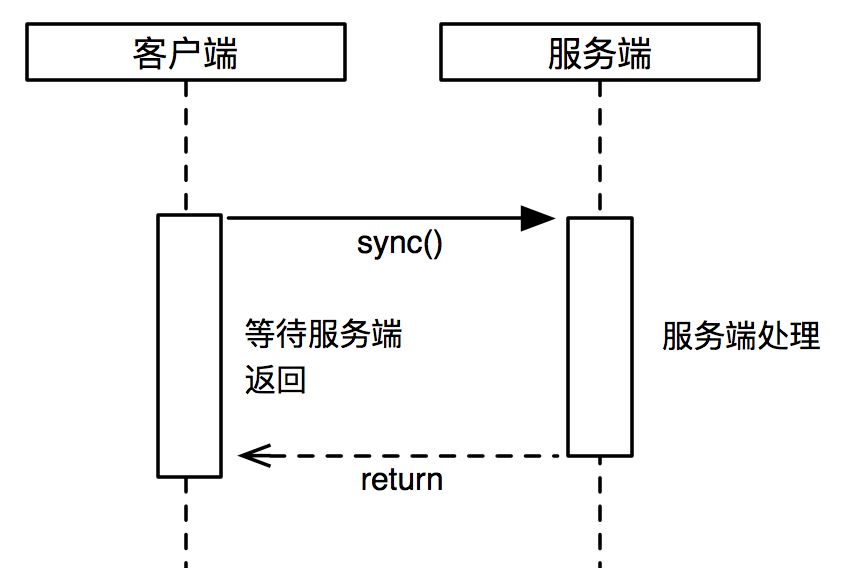
异步带回调接口,用在任务处理时间较长,客户端应用线程不愿阻塞等待,而是为了提高自身处理能力希望服务端处理完成后可以异步通知应用线程。这种方式可以大大提升客户端的吞吐量,避免因为服务端的耗时问题拖死客户端。
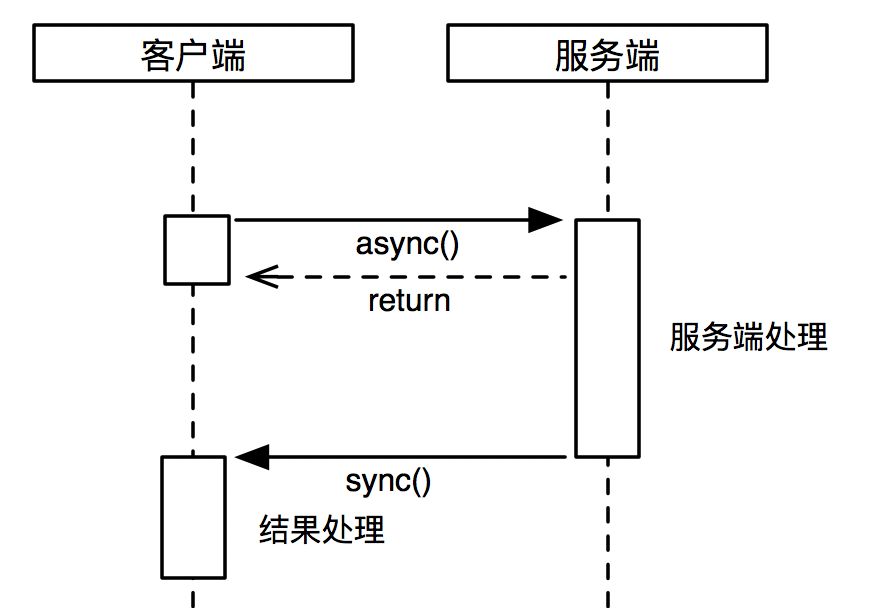
异步不带回调接口,一些场景为了进一步提升客户端的吞吐能力,只需发起一次服务端调用,不需关系调用结果,可以使用此种通信方式。一般在不需要严格保证数据一致性或者有其他补偿措施的情况下,选用这种,可以最小化远程调用带来的性能损耗。
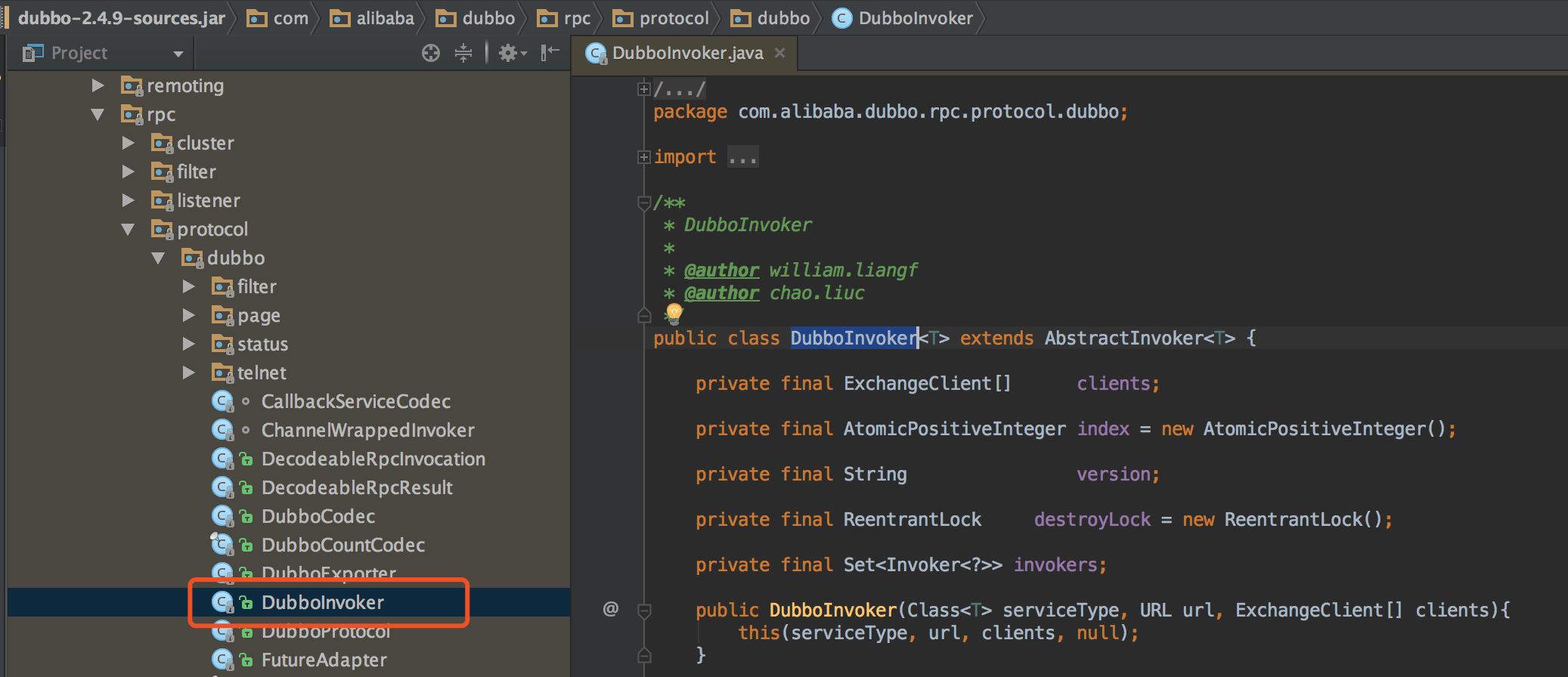
来看一下 Dubbo 是如何实现这三种 API 的。核心代码在 com.alibaba.dubbo.rpc.protocol.dubbo.DubboInvoker,如下图对应的位置,属于协议层的实现部分。为方便大家可以准确定位代码所在位置,使用截图的方式,而不是直接贴代码了。
上文描述的是三种 API 方式,Dubbo 里面通过参数 isOneway、isAsync 来控制,isOneway=true 表示异步不带回调,isAsync=true 表示异步带回调,否则是同步 API。具体是如何控制,看以下代码:
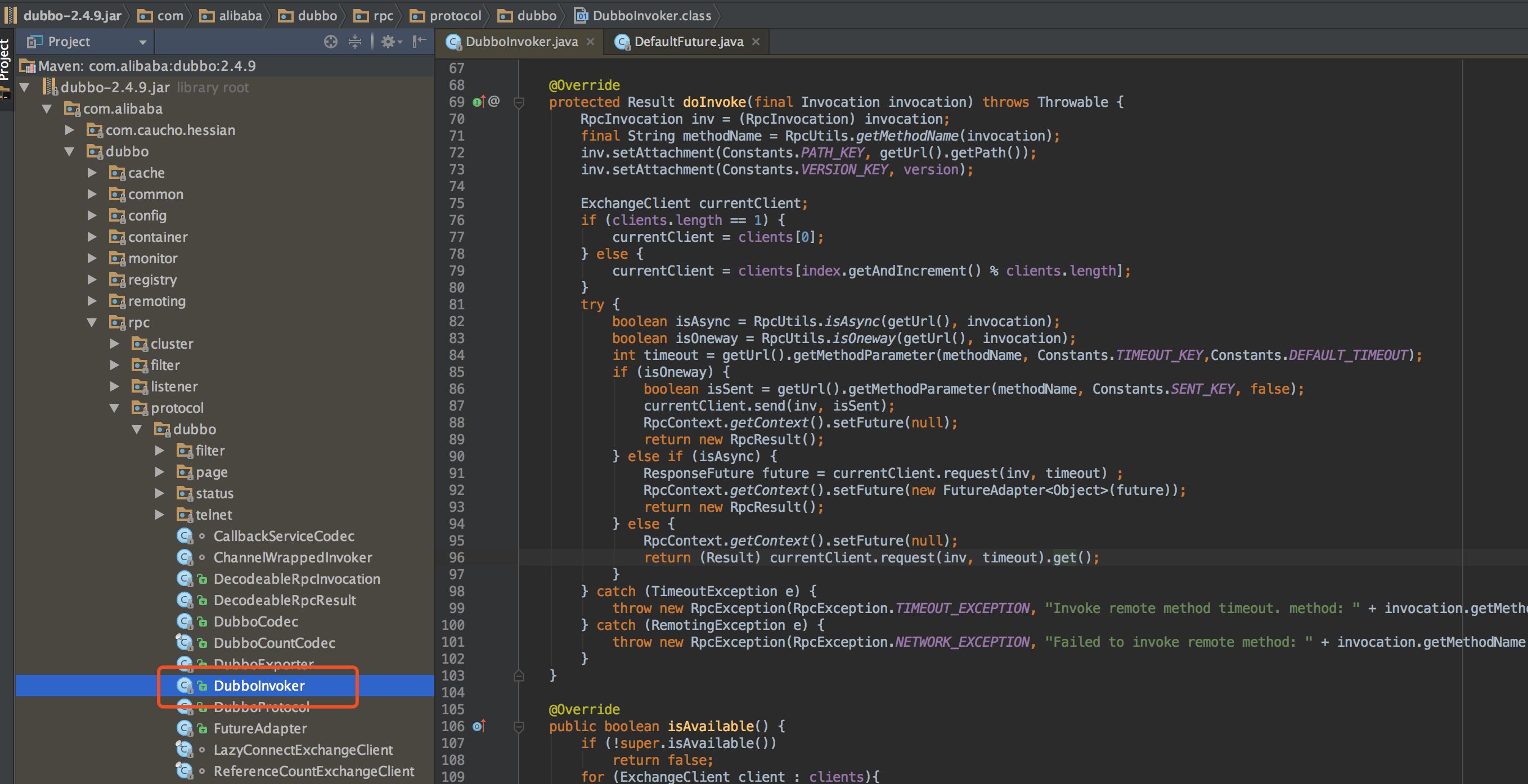
isOneway==true 时,客户端 send 完请求后,直接 return 一个空结果的 RpcResult;isAsync==true 时,客户端发起请求,设置一个 ResponseFuture,直接 return 一个空结果的 RpcResult,接下来当服务端处理完成,客户端 Netty 层在收到响应后会通过 Future 通知应用线程;最后是同步情况下,客户端发起请求,并通过 get() 方法阻塞等待服务端的响应结果。
异步 API 情况下,结合 NIO 模型比较好理解是如何实现的(当然需要先了解 NIO 的 reactor 模型),接下来重点理解下,这个 get() 阻塞方法是如何做到基于非阻塞 NIO 实现同步阻塞效果。
直接进入 get() 方法内部。
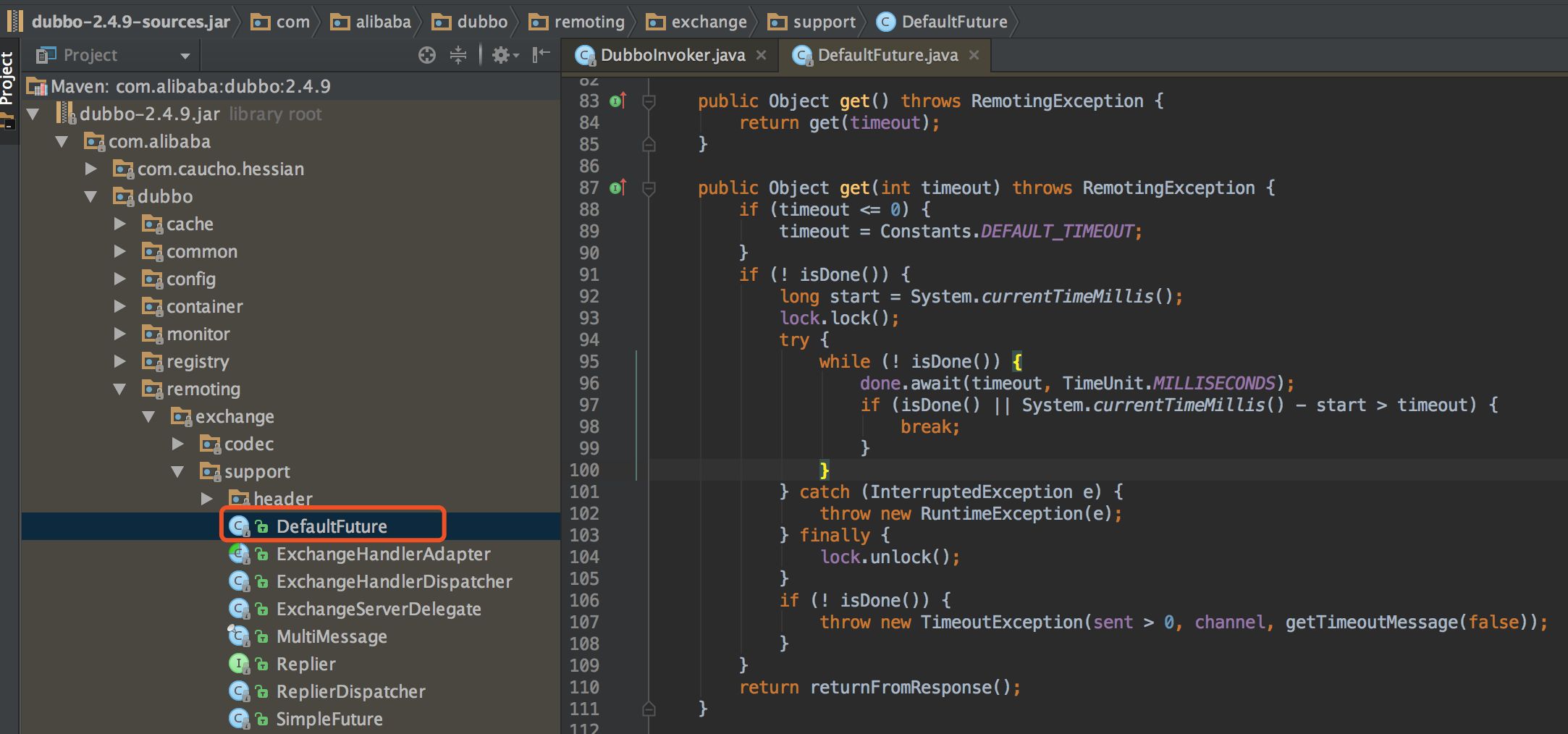
可以看到是利用 Java 的锁机制实现,循环判断是否收到响应,如果收到或者等待超时则返回。done 的实例对象如下:
private final Lock lock = new ReentrantLock();private final Condition done = lock.newCondition();使用可重入锁 ReentrantLock,获取一个 Condition 对象在其上做 await 操作。这里有 await 操作,何时被唤醒呢,有两个条件,第一个是等待 timeout 超时,默认 dubbo 是 1s,第二个就是被其他线程唤醒,即收到了服务端的响应。

signal 信号一发出,上文循环检测内的 await 操作会立即返回,下一次 isDone 判断会变成 true,直接跳出循环。
仔细看代码会发现,被唤醒的地方还有一个是在 DefaultFuture 内部有一个超时轮询检测的线程,这个线程主要是处理响应超时后触发资源回收、记录异常日志等操作。
private static class RemotingInvocationTimeoutScan implements Runnable { public void run() { while (true) {
try { for (DefaultFuture future : FUTURES.values()) { if (future == null || future.isDone()) {
continue;
}
if (System.currentTimeMillis() - future.getStartTimestamp() future.getTimeout()) {
// create exception response.
Response timeoutResponse = new Response(future.getId());
// set timeout status.
timeoutResponse.setStatus(future.isSent() ? Response.SERVER_TIMEOUT : Response.CLIENT_TIMEOUT);
timeoutResponse.setErrorMessage(future.getTimeoutMessage(true));
// handle response.
DefaultFuture.received(future.getChannel(), timeoutResponse);
}
}
Thread.sleep(30);
} catch (Throwable e) { logger.error( Exception when scan the timeout invocation of remoting. , e);
}
}
}
}
static { Thread th = new Thread(new RemotingInvocationTimeoutScan(), DubboResponseTimeoutScanTimer
th.setDaemon(true);
th.start();
}
可能会有疑问,这个触发操作为何不直接在 get() 方法内部检测到超时直接调用 DefaultFuture.received(Channel channel, Response response) 来清理,而是要额外开启一个后台线程。
单独启动一个超时线程有两个好处:
提高超时精度
get() 方法内部的轮询有一个 timeout,每次超时唤醒的时间间隔至少是 timeout 时长,最差的情况可能会等待 2 *timeout 作出超时反应。在超时轮询线程中,每隔 30ms 遍历检测一次,可以很大程度的提升超时精度。
2. 提升性能,降低响应时间
剥离超时处理逻辑到一个单独线程,可以减少对业务线程的时间占用,这个超时后的处理对应用来说并无直接作用,完全可以放到后台异步去处理。另外单独在一个线程中,实际上有批量处理的表现。
以上是就 NIO 通信基础上实现三种 API 调用的实现原理,或许有更多优于 Dubbo 的处理方式,可以拿出来讨论。
上述内容就是 RPC 框架 Dubbo 中非阻塞通信下的同步 API 实现原理是什么,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注丸趣 TV 行业资讯频道。











