共计 6373 个字符,预计需要花费 16 分钟才能阅读完成。
如何利用 Prometheus Operator 实现自定义指标监控,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面丸趣 TV 小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
在过去的文章中,我们花了相当大的篇幅来聊关于监控的话题。这是因为当你正在管理 Kubernetes 集群时,一切都会以极快的速度发生变化。因此有一个工具来监控集群的健康状态和资源指标极为重要。
在 Rancher 2.5 中,我们引入了基于 Prometheus Operator 的新版监控,它可以提供 Prometheus 以及相关监控组件的原生 Kubernetes 部署和管理。Prometheus Operator 可以让你监控集群节点、Kubernetes 组件和应用程序工作负载的状态和进程。同时,它还能够通过 Prometheus 收集的指标来定义告警并且创建自定义仪表盘,通过 Grafana 可以轻松地可视化收集到的指标。
新版本的监控也采用 prometheus-adapter,开发人员可以利用其基于自定义指标和 HPA 扩展他们的工作负载。
我们将探索如何利用 Prometheus Operator 来抓取自定义指标并利用这些指标进行高级工作负载管理。
安装 Prometheus
在 Rancher 2.5 中安装 Prometheus 极为简单。仅需访问 Cluster Explorer – Apps 并安装 rancher-monitoring 即可。

你需要了解以下默认设置:
prometheus-adapter 将会作为 chart 安装的一部分启用
ServiceMonitorNamespaceSelector 留为空,允许 Prometheus 在所有命名空间中收集 ServiceMonitors
安装完成后,我们可以从 Cluster Explorer 访问监控组件。

部署工作负载
现在让我们部署一个从应用层暴露自定义指标的示例工作负载。该工作负载暴露了一个简单的应用程序,该应用程序已经使用 Prometheus client_golang 库进行了检测,并在 /metric 端点上提供了一些自定义指标。
它有两个指标:
http_requests_total
http_request_duration_seconds
以下 manifest 部署了工作负载、相关服务以及访问该工作负载的 ingress:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: prometheus-example-app
name: prometheus-example-app
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: prometheus-example-app
template:
metadata:
labels:
app.kubernetes.io/name: prometheus-example-app
spec:
containers:
- name: prometheus-example-app
image: gmehta3/demo-app:metrics
ports:
- name: web
containerPort: 8080
apiVersion: v1
kind: Service
metadata:
name: prometheus-example-app
labels:
app.kubernetes.io/name: prometheus-example-app
spec:
selector:
app.kubernetes.io/name: prometheus-example-app
ports:
- protocol: TCP
port: 8080
targetPort: 8080
name: web
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: prometheus-example-app
spec:
rules:
- host: hpa.demo
http:
paths:
- path: /
backend:
serviceName: prometheus-example-app
servicePort: 8080
部署 ServiceMonitor
ServiceMonitor 是一个自定义资源定义(CRD),可以让我们声明性地定义如何监控一组动态服务。
你可以访问以下链接查看完整的 ServiceMonitor 规范:
https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/api.md#servicemonitor
现在,我们来部署 ServiceMonitor,Prometheus 用它来收集组成 prometheus-example-app Kubernetes 服务的 pod。
kind: ServiceMonitor
metadata:
name: prometheus-example-app
spec:
selector:
matchLabels:
app.kubernetes.io/name: prometheus-example-app
endpoints:
- port: web如你所见,现在用户可以在 Rancher 监控中浏览 ServiceMonitor。
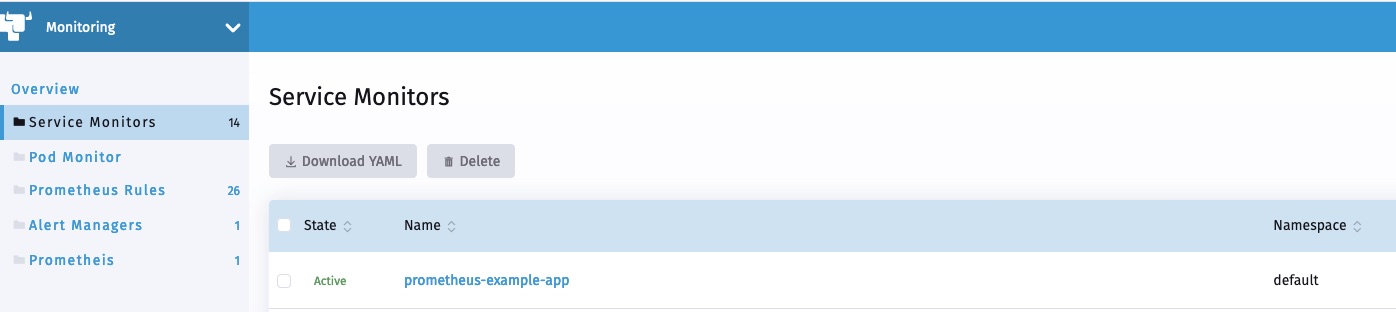
不久之后,新的 service monitor 和服务相关联的 pod 应该会反映在 Prometheus 服务发现中。

我们也能够在 Prometheus 中看到指标。

部署 Grafana 仪表盘
在 Rancher 2.5 中,监控可以让用户将 Grafana 仪表盘存储为 cattle-dashboards 命名空间中的 ConfigMaps。
用户或集群管理员现在可以在这一命名空间中添加更多的仪表盘以扩展 Grafana 的自定义仪表盘。
Dashboard ConfigMap ExampleapiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-example-app-dashboard
namespace: cattle-dashboards
labels:
grafana_dashboard: 1
data:
prometheus-example-app.json: |
{
annotations : {
list : [
{
builtIn : 1,
datasource : -- Grafana -- ,
enable : true,
hide : true,
iconColor : rgba(0, 211, 255, 1) ,
name : Annotations Alerts ,
type : dashboard
}
]
},
editable : true,
gnetId : null,
graphTooltip : 0,
links : [],
panels : [
{ aliasColors : {},
bars : false,
dashLength : 10,
dashes : false,
datasource : null,
fieldConfig : {
defaults : { custom : {}
},
overrides : []
},
fill : 1,
fillGradient : 0,
gridPos : {
h : 9,
w : 12,
x : 0,
y : 0
},
hiddenSeries : false,
id : 2,
legend : {
avg : false,
current : false,
max : false,
min : false,
show : true,
total : false,
values : false
},
lines : true,
linewidth : 1,
nullPointMode : null ,
percentage : false,
pluginVersion : 7.1.5 ,
pointradius : 2,
points : false,
renderer : flot ,
seriesOverrides : [],
spaceLength : 10,
stack : false,
steppedLine : false,
targets : [
{ expr : rate(http_requests_total{code=\ 200\ ,service=\ prometheus-example-app\}[5m]) ,
instant : false,
interval : ,
legendFormat : ,
refId : A
}
],
thresholds : [],
timeFrom : null,
timeRegions : [],
timeShift : null,
title : http_requests_total_200 ,
tooltip : {
shared : true,
sort : 0,
value_type : individual
},
type : graph ,
xaxis : {
buckets : null,
mode : time ,
name : null,
show : true,
values : []
},
yaxes : [
{
format : short ,
label : null,
logBase : 1,
max : null,
min : null,
show : true
},
{
format : short ,
label : null,
logBase : 1,
max : null,
min : null,
show : true
}
],
yaxis : {
align : false,
alignLevel : null
}
},
{ aliasColors : {},
bars : false,
dashLength : 10,
dashes : false,
datasource : null,
description : ,
fieldConfig : {
defaults : { custom : {}
},
overrides : []
},
fill : 1,
fillGradient : 0,
gridPos : {
h : 8,
w : 12,
x : 0,
y : 9
},
hiddenSeries : false,
id : 4,
legend : {
avg : false,
current : false,
max : false,
min : false,
show : true,
total : false,
values : false
},
lines : true,
linewidth : 1,
nullPointMode : null ,
percentage : false,
pluginVersion : 7.1.5 ,
pointradius : 2,
points : false,
renderer : flot ,
seriesOverrides : [],
spaceLength : 10,
stack : false,
steppedLine : false,
targets : [
{ expr : rate(http_requests_total{code!=\ 200\ ,service=\ prometheus-example-app\}[5m]) ,
interval : ,
legendFormat : ,
refId : A
}
],
thresholds : [],
timeFrom : null,
timeRegions : [],
timeShift : null,
title : http_requests_total_not_200 ,
tooltip : {
shared : true,
sort : 0,
value_type : individual
},
type : graph ,
xaxis : {
buckets : null,
mode : time ,
name : null,
show : true,
values : []
},
yaxes : [
{
format : short ,
label : null,
logBase : 1,
max : null,
min : null,
show : true
},
{
format : short ,
label : null,
logBase : 1,
max : null,
min : null,
show : true
}
],
yaxis : {
align : false,
alignLevel : null
}
}
],
schemaVersion : 26,
style : dark ,
tags : [],
templating : { list : []
},
time : {
from : now-15m ,
to : now
},
timepicker : {
refresh_intervals : [
5s ,
10s ,
30s ,
1m ,
5m ,
15m ,
30m ,
1h ,
2h ,
1d
]
},
timezone : ,
title : prometheus example app ,
version : 1
}
现在,用户应该能够在 Grafana 中访问 prometheus example app 的仪表盘。

自定义指标的 HPA
这一部分假设你已经将 prometheus-adapter 作为监控的一部分安装完毕了。实际上,在默认情况下,监控安装程序会安装 prometheus-adapter。
用户现在可以创建一个 HPA spec,如下所示:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: prometheus-example-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: prometheus-example-app
minReplicas: 1
maxReplicas: 5
metrics:
- type: Object
object:
describedObject:
kind: Service
name: prometheus-example-app
metric:
name: http_requests
target:
averageValue: 5
type: AverageValue
你可以查看以下链接获取关于 HPA 的更多信息:
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
我们将使用自定义的 http_requests_total 指标来执行 pod 自动伸缩。

现在我们可以生成一个样本负载来查看 HPA 的运行情况。我可以使用 hey 进行同样的操作。
hey -c 10 -n 5000 http://hpa.demo
开发人员和集群管理员可以利用该堆栈来监控它们的工作负载,部署可视化,并利用 Kubernetes 内可用的高级工作负载管理功能。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注丸趣 TV 行业资讯频道,感谢您对丸趣 TV 的支持。











