共计 3200 个字符,预计需要花费 8 分钟才能阅读完成。
这篇文章给大家介绍 kafka-Storm 中如何将日志文件打印到 local,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
阅读前提:
1:您可能需要对 logback 日志系统有所了解
2:您可能需要对于 kafka 有初步的了解
3:请代码查看之前,请您仔细参考系统的业务图解
由于 kafka 本身自带了和『Hadoop』的接口,如果需要将 kafka 中的文件直接迁移到 HDFS,请参看本 ID 的另外一篇博文:
业务系统 -kafka-Storm【日志本地化】– 2:直接通过 kafka 将日志传递到 HDFS
1:一个正式环境系统的系统设计图解:
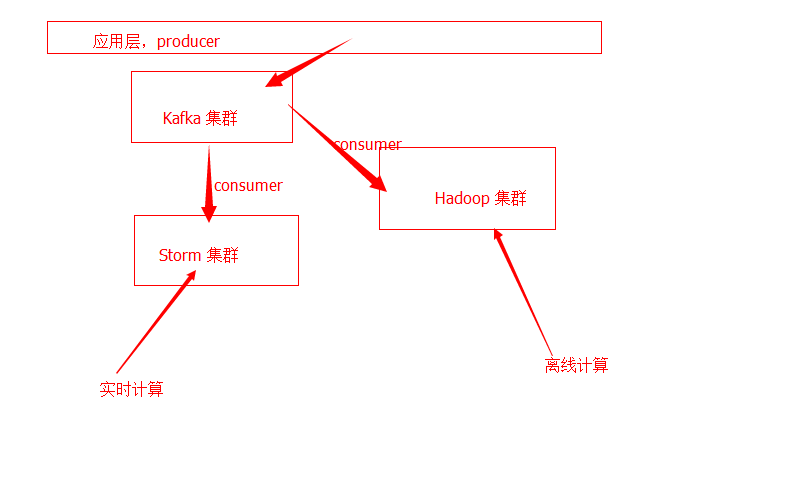
通过 kafka 集群,在 2 个相同的 topic 之下,通过 kafka-storm, he kafka-hadoop,2 个 Consumer,针对同样的一份数据,我们分流了 2 个管道:
其一:实时通道
其二:离线通道
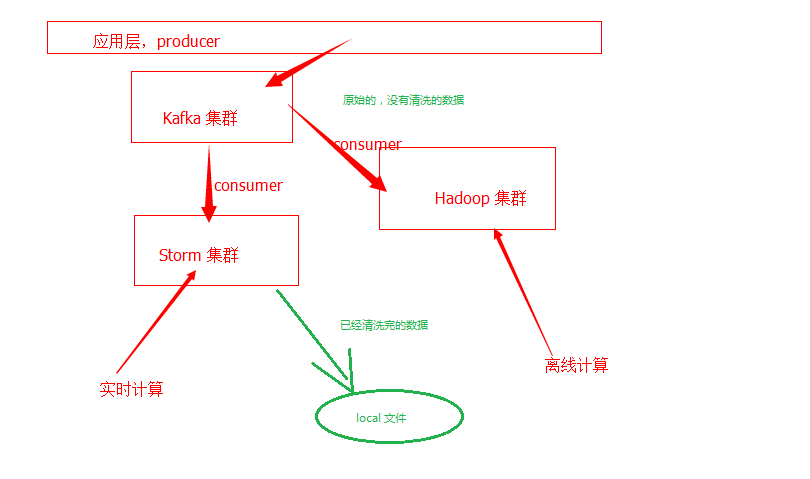
在日志本地化的过程之中,前期,由于日志的清洗,过滤的工作是放在 Storm 集群之中,也就是说,留存到本地 locla 的日志。是我们在 Storm 集群之中进行了清洗的数据。
也就是:
如下图所示:
在 kafka 之中,通常而言,有如下的 代码 用来处理:
在这里我们针对了 2 种日志,有两个 Consumer 用来处理
package com.mixbox.kafka.consumer;
public class logSave {public static void main(String[] args) throws Exception {Consumer_Thread visitlog = new Consumer_Thread(KafkaProperties.visit);
visitlog.start();
Consumer_Thread orderlog = new Consumer_Thread(KafkaProperties.order);
orderlog.start();}
在这里,我们依据不同的原始字段,将不同的数据保存到不同的文件之中。
package com.mixbox.kafka.consumer;
import java.io.UnsupportedEncodingException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
* @author Yin Shuai
*/
public class Consumer_Thread extends Thread {
// 在事实上我们会依据传递的 topic 名称,来生成不桐的记录机器
// private Logger _log_order = LoggerFactory.getLogger( order
// private Logger _log_visit = LoggerFactory.getLogger( visit
private Logger _log = null;
private final ConsumerConnector _consumer;
private final String _topic;
public Consumer_Thread(String topic) {
_consumer = kafka.consumer.Consumer
.createJavaConsumerConnector(createConsumerConfig());
this._topic = topic;
_log = LoggerFactory.getLogger(_topic);
System.err.println(log 的名称 + _topic);
private static ConsumerConfig createConsumerConfig() {Properties props = new Properties();
props.put(zookeeper.connect , KafkaProperties.zkConnect);
// 在这里我们的组 ID 为 logSave
props.put(group.id , KafkaProperties.logSave);
props.put( zookeeper.session.timeout.ms , 100000
props.put( zookeeper.sync.time.ms , 200
props.put( auto.commit.interval.ms , 1000
return new ConsumerConfig(props);
public void run() {
Map String, Integer topicCountMap = new HashMap String, Integer
topicCountMap.put(_topic, new Integer(1));
Map String, List KafkaStream byte[], byte[] consumerMap = _consumer
.createMessageStreams(topicCountMap);
for (KafkaStream byte[], byte[] kafkaStream : consumerMap.get(_topic)) {ConsumerIterator byte[], byte[] iterator = kafkaStream.iterator();
while (iterator.hasNext()) {MessageAndMetadata byte[], byte[] next = iterator.next();
try {
// 在这里我们分拆了一个 Consumer 来处理 visit 日志
logFile(next);
System.out.println( message:
+ new String(next.message(), utf-8 ));
} catch (UnsupportedEncodingException e) {e.printStackTrace();
private void logFile(MessageAndMetadata byte[], byte[] next)
throws UnsupportedEncodingException {_log.info(new String(next.message(), utf-8 ));
}一个简单的小 tips:
logback.xml , 提醒您注意,这里的配置文件太过粗浅。如有需要,请自行填充。
?xml version= 1.0 encoding= UTF-8 ?
configuration
jmxConfigurator /
!-- 控制台输出日志 --
appender name= STDOUT >关于 kafka-Storm 中如何将日志文件打印到 local 就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。











