共计 4352 个字符,预计需要花费 11 分钟才能阅读完成。
丸趣 TV 小编给大家分享一下 PostgreSQL 如何实现并行查询,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
并行查询的背景
随着 SSD 等磁盘技术的平民化,以及动辄上百 GB 内存的普及,I/ O 层面的性能问题得到了有效缓解。提升数据库的扩展性能,可以追求 Scale Out 的方式,增加机器,往分布式方向发展,也可以追求 Scale Up,增加硬件组件,充分利用各个硬件的资源,把单机的性能发挥到最大效果。相较而言,Scale Up 通过软件加速性能,依赖软件层面的优化,是低成本的扩展方案。
现代服务器除了磁盘和内存资源的增强,多 CPU 的配置也足够强大。数据库的 Join、聚合等操作内存耗费比较大,很多时间花在了数据的交换和缓存上,CPU 的利用率并不高,所以面向 CPU 的加速策略中,并发执行是一种常见的方法。
查询的性能是评价 OLAP 型数据库产品好坏的核心指标,而并行查询可以聚焦在数据的读和计算上,通过把 Join、聚合、排序等操作分解成多个操作实现并行。
并行查询的挑战在于,为了要做并行而加入的数据分片过程、进程或线程间的通信,以及并发控制方面带来的系统开销不但没有增加性能,反而降低了原有性能。实现上,如何在优化器里规划好并行计划也是很多数据库做不到的。
PostgreSQL 的并行查询功能主要由 PostgreSQL 社区的核心开发者 Robert Haas 等人开发。从 Robert Haas 的个人博客了解到,社区开发 PostgreSQL 的并行查询特性时间表如下:
2013 年 10 月,执行框架上做了 Dynamic Background Workers 和 Dynamic Shared Memory 两个调整
2014 年 12 月,Amit Kapila 提交了一个简单版的 parallel sequential scan 的 patch;
2015 年 3 月,正式版的 parallel sequential scan 的 patch 被提交;
2016 年 3 月,支持 parallel joins 和 parallel aggregation;
2016 年 4 月,作为 9.6 的新特性发布。
PostgreSQL 的并行查询在大数据量(中间结果在 GB 以上)的 Join、Merge 场合,效果比较明显。效果上,因为系统开销,投入的资源跟性能提升并不是线性的,比如增加 4 个 worker,性能则可能提升 2 倍左右,而不是 4 倍。通过 TPCH 的测试效果,表明在 Ad-Hoc 查询场景,普遍都有加速效果。
并行查询功能说明
现在支持的并行场景主要是以下 3 种:
parallel sequential scan
parallel join
parallel aggregation
鉴于安全考虑,以下 4 种场景不支持并行:
公共表表达式(CTE)的扫描
临时表的扫描
外部表的扫描(除非外部数据包装器有一个 IsForeignScanParallelSafeAPI)
对 InitPlan 或 SubPlan 的访问
使用并行查询,还有以下限制:
必须保证是严格的 read only 模式,不能改变 database 的状态
查询执行过程中,不能被挂起
隔离级别不能是 SERIALIZABLE
不能调用 PARALLEL UNSAFE 函数
并行查询有基于代价策略的判断,譬如小数据量时默认还是普通执行。在 PostgreSQL 的配置参数中,提供了一些跟并行查询相关的参数。我们想测试并行,一般设置下面两个参数:
force_parallel_mode:强制开启并行模式的开关
max_parallel_workers_per_gather:设定用于并行查询的 worker 进程数
一个简单的两表 Join 查询场景,使用并行查询模式的查询计划如下:


并行查询开启后,解析器会生成一份 Gather…Partial 风格的执行计划,这意味着到 Executor 层,会将 Partial 部分的计划并行执行。
执行计划里可以看到,在做并行查询时,额外创建了 2 个 worker 进程,加上原来的 master 进程,总共 3 个进程。Join 的驱动表数据被平均分配了 3 份,通过并行 scan 分散了 I / O 操作,之后跟大表数据分别做 Join。
并行查询的实现
PostgreSQL 的并行由多个进程的机制完成。每个进程在内部称之为 1 个 worker,这些 worker 可以动态地创建、销毁。PostgreSQL 在 SQL 语句解析和生成查询计划阶段并没有并行。在执行器(Executor)模块,由多个 worker 并发执行被分片过的子任务。即使在查询计划被并行执行的环节,一直存在的进程也会充当一个 worker 来完成并行的子任务,我们可以称之为主进程。同时,根据配置参数指定的 worker 数,再启动 n 个 worker 进程来执行其他子计划。
PostgreSQL 内延续了共享内存的机制,在每个 worker 初始化时就为每个 worker 分配共享内存,用于 worker 各自获取计划数据和缓存中间结果。这些 worker 间没有复杂的通信机制,而是都由主进程做简单的通信,来启动和执行计划。
PostgreSQL 中并行的执行模型如图 1 所示。
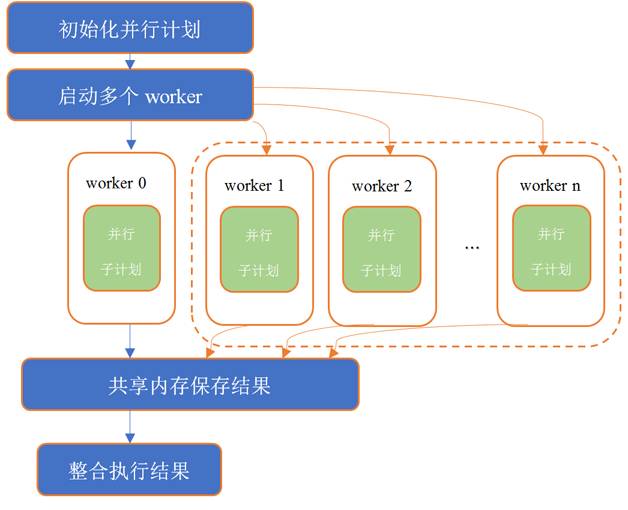
图 1 PostgreSQL 并行查询的框架
以上文的 Hash Join 的场景为例,在执行器层面,并行查询的执行流程如图 2 所示。
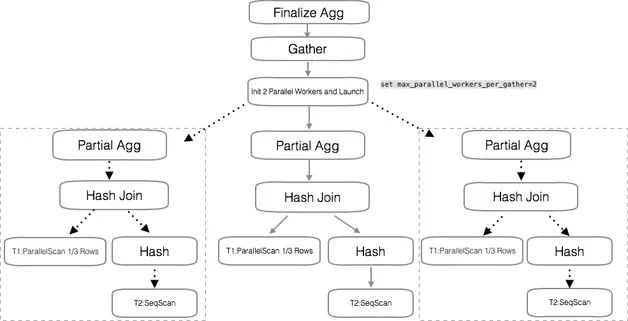
图 2 并行查询的执行流程
各 worker 按照以下方式协同完成执行任务:
首先,每个 worker 节点做的任务相同。因为是 Hash Join,worker 节点使用一个数据量小的表作为驱动表,做 Hash 表。每个 worker 节点都会维护这样一个 Hash 表,而大表被平均分之后跟 Hash 表做数据 Join。
最底层的并行是磁盘的并行 scan,worker 进程可以从磁盘 block 里获取自己要 scan 的 block。
Hash Join 后的数据是全部数据的子集。对于 count() 这种聚合函数,数据子集上可以分别做计算,最后再合并,结果上可以保证正确。
数据整合后,做一次总的聚合操作。
worker 进程又是如何创建和运行的?首先来看 worker 的创建逻辑(参见图 3)。
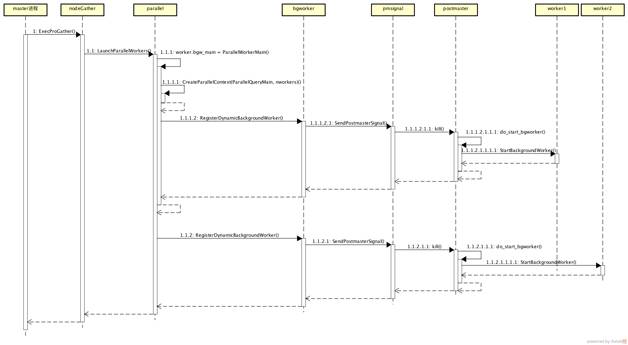
图 3 PostgreSQL 的 worker 创建
PostgreSQL 的并行处理,以 worker 动态创建为前提。worker 可以由主进程初始化出来,并且在上下文中,先指定好入口函数。
并行查询中,入口函数被指定为 ParallelWorkerMain。而 ParallelWorkerMain 函数里,在完成一系列信号代理设定后,会调用 ParallelQueryMain 来执行查询。ParallelQueryMain 创建了一个新的执行器上下文,递归执行并行子查询计划。
用来并行查询的 worker 进程接收主进程的信号,比如一旦发送创建进程的信号,worker 进程就会启动,紧接着执行 ParallelWorkerMain 函数。进而,ParallelQueryMain 也会执行,各个 worker 进程独立执行子计划,执行结果会存在共享内存里。所有进程执行结束后,master 进程会去搜集共享内存里的结果数据(tuple),做数据整合。
并行查询的改进
并行查询的特性公布后,不乏对并行的评价和之后的改进计划。社区并行查询的开发者在博客中提到准备做一个大的共享 Hash Table,这样 Hash Join 操作的并行度会进一步提升。
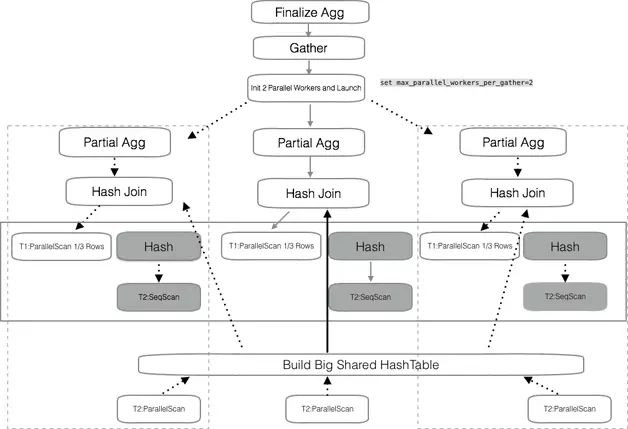
图 4 创建大的 Hash 表共享数据
另外,对 PostgreSQL 而言,反倒是基于其 folk 出来的一些数据库产品先于它做了并行查询的特性,可以学习参考:
Postgres-XC 的分布式框架
GreenPlum 的 MPP 架构
CitusDB 的分布式
VitesseDB 基于多线程的并行
Fujitsu 的 Fujitsu Enterprise PostgreSQL 的并行
其中开源数据库 GreenPlum 并行架构很有借鉴意义。GreenPlum 的并行查询设计了一个专门的调度器来协调查询任务的分配,而 PostgreSQL 没有这样的设计。关于 GreenPlum 的执行框架,简单讲是以下三层结构:
调度器(QD):调度器发送优化后的查询计划给所有数据节点(Segments)上的执行器(QE)。调度器负责任务的执行,包括执行器的创建、销毁、错误处理、任务取消、状态更新等。
执行器(QE):执行器收到调度器发送的查询计划后,开始执行自己负责的那部分计划。典型的操作包括数据扫描、哈希关联、排序、聚集等。
Interconnect:负责集群中各个节点间的数据传输
GreenPlum 会根据数据分布情况做数据的广播和重分布,这是 PostgreSQL 的并行模型可以借鉴的。
仅仅是一个大的 Hash Table,在数据访问上有串行的开销,worker 的并行仍然受限。如图 5 所示,大表和小表 Join 的场景参考 GreenPlum 的数据广播机制,驱动表的数据可以给每个 worker 进程准备一个拷贝,相当于广播了一份数据。这样数据被高度共享,并行的效果会更好。
除了 PostgreSQL 生态的数据库,关系型数据库老大哥 Oracle 在并行查询上已经积累了 30 年的经验,也需要借鉴。在 Oracle 的官方手册中,有对其并行查询机制做出的说明。
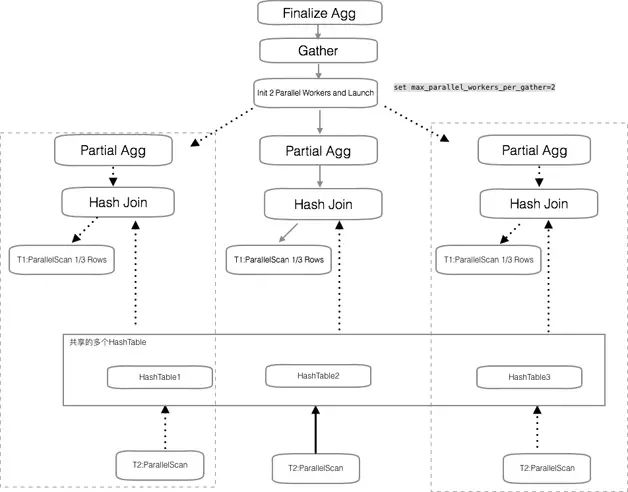
图 5 借鉴 GreenPlum 的广播机制提升并行效果
Oracle 在每个操作环节,都能把数据高度分片,可以参考图 6 所示的 Hash Join 的并行。
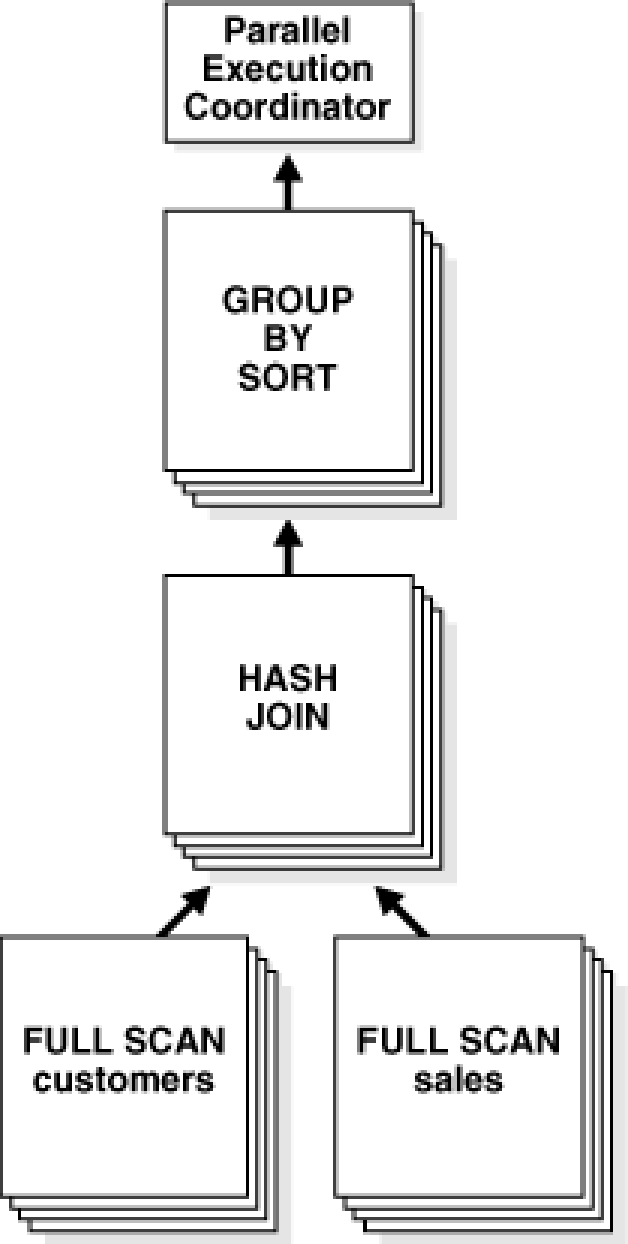
图 6 Oracle 的 Hash Join 操作的并行流程
而在内部并行控制上,数据被分组后,不管是 scan 还是排序,几组 worker 对分组的数据都能分治。
也就是说 Oracle 做到了操作符(Operator)Level 的并行。在每个操作中,把数据分片后动态的并行运算。可以看到 Oracle 的并行查询在做 Operator 级别的并行,每个操作环节,都能把数据分片后分而治之,并行程度非常高。这对数据的流转要求也很高,数据和操作既能水平分治也能垂直分治。
PostgreSQL 目前是任务级别的并行,将原先的执行计划垂直拆分成几个可以分离的子任务,并行实现简单,但在大数据量时并行度不够,而且共享内存的访问负荷加重,性能提升不明显。
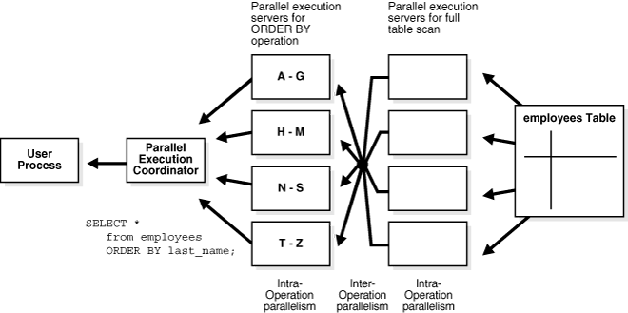
图 7 Oracle 内部动态的并行操作
参考 Oracle 的方式,按上图改进后,worker 不再是单独执行 1 个任务,而是随时被调用执行操作。数据根据操作分层、分片、广播,worker 进程为数据操作服务,而不是数据为 worker 服务。这样在超大规模数据的场景,驱动表作为 producer 做数据 partition,外表作为 consumer 做 operator 运算。多组这样的操作产生的并行计算更自由,性能也更有想象空间,也是我们团队目前在尝试的方向。
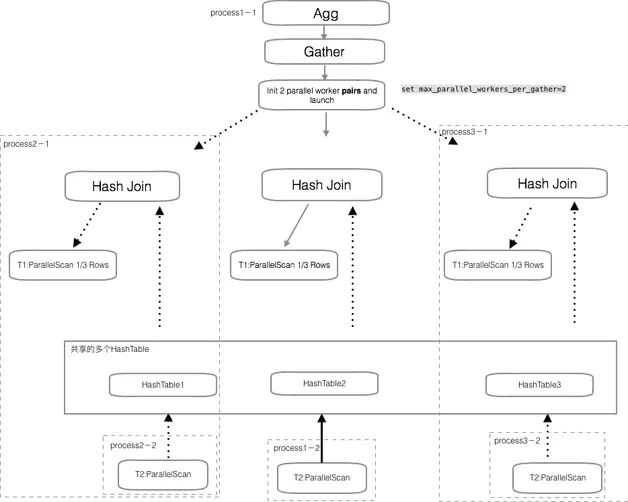
图 8 通过数据分组和 worker 分组提升 PostgreSQL 的并行
看完了这篇文章,相信你对“PostgreSQL 如何实现并行查询”有了一定的了解,如果想了解更多相关知识,欢迎关注丸趣 TV 行业资讯频道,感谢各位的阅读!











