共计 4580 个字符,预计需要花费 12 分钟才能阅读完成。
自动写代码机器人,免费开通
丸趣 TV 小编给大家分享一下 MySQL 选错索引导致的线上慢查询事故怎么办,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
正文故障描述
在 7 月 24 日 11 点线上某数据库突然收到大量告警,慢查询数超标,并且引发了连接数暴增,导致数据库响应缓慢,影响业务。看图表慢查询在高峰达到了每分钟 14w 次,在平时正常情况下慢查询数仅在两位数以下,如下图:

赶紧查看慢 SQL 记录,发现都是同一类语句导致的慢查询 (隐私数据例如表名,我已经隐去):
select
sample_table
where
1 = 1
and (city_id = 565)
and (type = 13)
order by
id desc
limit
0, 1 复制代码
看起来语句很简单,没什么特别的。但是每个执行的查询时间达到了惊人的 44s。

简直耸人听闻,这已经不是“慢”能形容的了 …
接下来查看表数据信息,如下图:

可以看到表数据量较大,预估行数在 83683240,也就是 8000w 左右,千万数据量的表。
大致情况就是这样,下面进入排查问题的环节。
问题原因排查
首先当然要怀疑会不会该语句没走索引,查看建表 DML 中的索引:
KEY `idx_1` (`city_id`,`type`,`rank`),
KEY `idx_log_dt_city_id_rank` (`log_dt`,`city_id`,`rank`),
KEY `idx_city_id_type` (`city_id`,`type`) 复制代码
请忽略 idx_1 和 idx_city_id_type 两个索引的重复,这都是历史遗留问题了。
可以看到是有 idx_city_id_type 和 idx_1 索引的,我们的查询条件是 city_id 和 type,这两个索引都是能走到的。
但是,我们的查询条件真的只要考虑 city_id 和 type 吗?(机智的小伙伴应该注意到问题所在了,先往下讲,留给大家思考)
既然有索引,接下来就该看该语句实际有没有走到索引了,MySQL 提供了 Explain 可以分析 SQL 语句。Explain 用来分析 SELECT 查询语句。
Explain 比较重要的字段有:
select_type : 查询类型,有简单查询、联合查询、子查询等 key : 使用的索引 rows : 预计需要扫描的行数
更多详细 Explain 介绍可以参考:MySQL 性能优化神器 Explain 使用分析
我们使用 Explain 分析该语句:
select * from sample_table where city_id = 565 and type = 13 order by id desc limit 0,1 复制代码 得到结果:

可以看出,虽然 possiblekey 有我们的索引,但是最后走了主键索引。而表是千万级别,并且该查询条件最后实际是返回的空数据,也就是 MySQL 在主键索引上实际检索时间很长,导致了慢查询。
我们可以使用 force index(idx_city_id_type) 让该语句选择我们设置的联合索引:
select * from sample_table force index(idx_city_id_type) where (( (1 = 1) and (city_id = 565) ) and (type = 13) ) order by id desc limit 0, 1 复制代码 这次明显执行的飞快,分析语句:

实际执行时间 0.00175714s,走了联合索引后,不再是慢查询了。
问题找到了,总结下来就是:MySQL 优化器认为在 limit 1 的情况下,走主键索引能够更快的找到那一条数据,并且如果走联合索引需要扫描索引后进行排序,而主键索引天生有序,所以优化器综合考虑,走了主键索引。实际上,MySQL 遍历了 8000w 条数据也没找到那个天选之人(符合条件的数据),所以浪费了很多时间。
MySQL 索引选择原理优化器索引选择的准则
MySQL 一条语句的执行流程大致如下图,而查询优化器则是选择索引的地方:
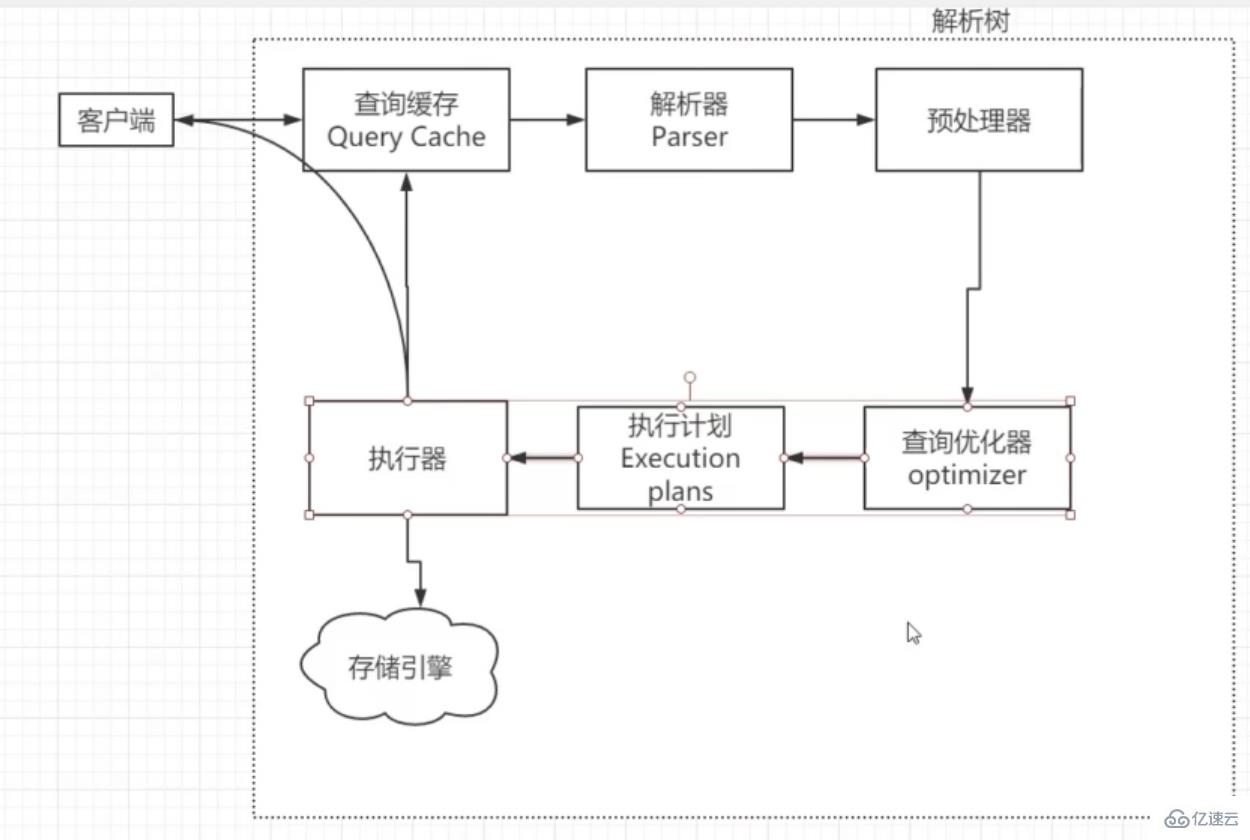
引用参考文献一段解释:
首先要知道,选择索引是 MySQL 优化器的工作。
而优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。在数据库里面,扫描行数是影响执行代价的因素之一。扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的 CPU 资源越少。
当然,扫描行数并不是唯一的判断标准,优化器还会结合是否使用临时表、是否排序等因素进行综合判断。
总结下来,优化器选择有许多考虑的因素:扫描行数、是否使用临时表、是否排序等等
我们回头看刚才的两个 explain 截图:


走了主键索引的查询语句,rows 预估行数 1833,而强制走联合索引行数是 45640,并且 Extra 信息中,显示需要 Using filesort 进行额外的排序。所以在不加强制索引的情况下,优化器选择了主键索引,因为它觉得主键索引扫描行数少,而且不需要额外的排序操作,主键索引天生有序。
rows 是怎么预估出来的
同学们就要问了,为什么 rows 只有 1833,明明实际扫描了整个主键索引啊, 行数远远不止几千行。实际上 explain 的 rows 是 MySQL 预估的行数,是根据查询条件、索引和 limit 综合考虑出来的预估行数。
MySQL 是怎样得到索引的基数的呢?这里,我给你简单介绍一下 MySQL 采样统计的方法。为什么要采样统计呢?因为把整张表取出来一行行统计,虽然可以得到精确的结果,但是代价太高了,所以只能选择“采样统计”。采样统计的时候,InnoDB 默认会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过 1 / M 的时候,会自动触发重新做一次索引统计。在 MySQL 中,有两种存储索引统计的方式,可以通过设置参数 innodb_stats_persistent 的值来选择:设置为 on 的时候,表示统计信息会持久化存储。这时,默认的 N 是 20,M 是 10。设置为 off 的时候,表示统计信息只存储在内存中。这时,默认的 N 是 8,M 是 16。由于是采样统计,所以不管 N 是 20 还是 8,这个基数都是很容易不准的。复制代码
我们可以使用 analyze table t 命令,可以用来重新统计索引信息。但是这条命令生产环境需要联系 DBA,所以我就不做实验了, 大家可以自行实验。
索引要考虑 order by 的字段
为什么这么说?因为如果我这个表中的索引是 city_id,type 和 id 的联合索引,那优化器就会走这个联合索引,因为索引已经做好了排序。
更改 limit 大小能解决问题?
把 limit 数量调大会影响预估行数 rows,进而影响优化器索引的选择吗?
答案是会。
我们执行 limit 10
select * from sample_table where city_id = 565 and type = 13 order by id desc limit 0,10 复制代码 
图中 rows 变为了 18211,增长了 10 倍。如果使用 limit 100,会发生什么?

优化器选择了联合索引。初步估计是 rows 还会翻倍,所以优化器放弃了主键索引。宁愿用联合索引后排序,也不愿意用主键索引了。
为何突然出现异常慢查询
问:这个查询语句已经在线上稳定运行了非常长的时间,为何这次突然出现了慢查询?
答:以前的语句查询条件返回结果都不为空,limit1 很快就能找到那条数据,返回结果。而这次代码中查询条件实际结果为空,导致了扫描了全部的主键索引。
解决方案
知道了 MySQL 为何选择这个索引的原因后,我们就可以根据上面的思路来列举出解决办法了。
主要有两个大方向:
强制指定索引干涉优化器选择强制选择索引:force index
就像上面我最开始的操作那样,我们直接使用 force index,让语句走我们想要走的索引。
select * from sample_table force index(idx_city_id_type) where (( (1 = 1) and (city_id = 565) ) and (type = 13) ) order by id desc limit 0, 1 复制代码 这样做的优点是见效快,问题马上就能解决。
缺点也很明显:
高耦合,这种语句写在代码里,会变得难以维护,如果索引名变化了,或者没有这个索引了,代码就要反复修改。属于硬编码。很多代码用框架封装了 SQL,force index() 并不容易加进去。
我们换一种办法,我们去引导优化器选择联合索引。
干涉优化器选择:增大 limit
通过增大 limit,我们可以让预估扫描行数快速增加,比如改成下面的 limit 0, 1000
SELECT * FROM sample_table where city_id = 565 and type = 13 order by id desc LIMIT 0,1000 复制代码 这样就会走上联合索引,然后排序,但是这样强行增长 limit,其实总有种面向黑盒调参的感觉。我们还有更优美的解决方案吗?
干涉优化器选择:增加包含 order by id 字段的联合索引
我们这句慢查询使用的是 order by id,但是我们却没有在联合索引中加入 id 字段,导致了优化器认为联合索引后还要排序,干脆就不太想走这个联合索引了。
我们可以新建 city_id,type 和 id 的联合索引,来解决这个问题。
这样也有一定的弊端,比如我这个表到了 8000w 数据,建立索引非常耗时,而且通常索引就有 3.4 个 g,如果无限制的用索引解决问题,可能会带来新的问题。表中的索引不宜过多。
干涉优化器选择:写成子查询
还有什么办法?我们可以用子查询,在子查询里先走 city_id 和 type 的联合索引,得到结果集后在 limit1 选出第一条。
但是子查询使用有风险,一版 DBA 也不建议使用子查询,会建议大家在代码逻辑中完成复杂的查询。当然我们这句并不复杂啦~
Select * From sample_table Where id in (Select id From `newhome_db`.`af_hot_price_region` where (city_id = 565 and type = 13)) limit 0, 1 复制代码 还有很多解决办法 …
SQL 优化是个很大的工程,我们还有非常多的办法能够解决这句慢查询问题,这里就不一一展开了。留给大家做为思考题了。
总结
本文带大家回顾了一次 MySQL 优化器选错索引导致的线上慢查询事故,可以看出 MySQL 优化器对于索引的选择并不单单依靠某一个标准,而是一个综合选择的结果。我自己也对这方面了解不深入,还需要多多学习,争取能够好好的做一个索引选择的总结(挖坑)。不说了,拿起巨厚的《高性能 MySQL》, 开始 …
压住我的泡面 …
最后做个文章总结:
该慢查询语句中使用 order by id 导致优化器在主键索引和 city_id 和 type 的联合索引中有所取舍,最终导致选择了更慢的索引。可以通过强制指定索引,建立包含 id 的联合索引,增大 limit 等方式解决问题。平时开发时,尤其是对于特大数据量的表,要注意 SQL 语句的规范和索引的建立,避免事故的发生。
以上是 MySQL 选错索引导致的线上慢查询事故怎么办的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注丸趣 TV 行业资讯频道!
向 AI 问一下细节丸趣 TV 网 – 提供最优质的资源集合!











