共计 2339 个字符,预计需要花费 6 分钟才能阅读完成。
自动写代码机器人,免费开通
这篇文章主要介绍 MySQL 统计信息的存储有哪几种,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
MySQL 统计信息的存储分为两种,非持久化和持久化统计信息。
一、非持久化统计信息
非持久化统计信息存储在内存里,如果数据库重启,统计信息将丢失。有两种方式可以设置为非持久化统计信息:
1 全局变量,
INNODB_STATS_PERSISTENT=OFF
2 CREATE/ALTER 表的参数,
STATS_PERSISTENT=0
非持久化统计信息在以下情况会被自动更新:
1 执行 ANALYZE TABLE
2 innodb_stats_on_metadata=ON 情况下,执 SHOW TABLE STATUS, SHOW INDEX, 查询 INFORMATION_SCHEMA 下的 TABLES, STATISTICS
3 启用 –auto-rehash 功能情况下,使用 mysql client 登录
4 表第一次被打开
5 距上一次更新统计信息,表 1 /16 的数据被修改
非持久化统计信息的缺点显而易见,数据库重启后如果大量表开始更新统计信息,会对实例造成很大影响,所以目前都会使用持久化统计信息。
二、持久化统计信息
5.6.6 开始,MySQL 默认使用了持久化统计信息,即 INNODB_STATS_PERSISTENT=ON,持久化统计信息保存在表 mysql.innodb_table_stats 和 mysql.innodb_index_stats。
持久化统计信息在以下情况会被自动更新:
1 INNODB_STATS_AUTO_RECALC=ON
情况下,表中 10% 的数据被修改
2 增加新的索引
innodb_table_stats 是表的统计信息,innodb_index_stats 是索引的统计信息,各字段含义如下:
innodb_table_stats
database_name
数据库名
table_name
表名
last_update
统计信息最后一次更新时间
n_rows
表的行数
clustered_index_size
聚集索引的页的数量
sum_of_other_index_sizes
其他索引的页的数量
innodb_index_stats
database_name
数据库名
table_name
表名
index_name
索引名
last_update
统计信息最后一次更新时间
stat_name
统计信息名
stat_value
统计信息的值
sample_size
采样大小
stat_description
类型说明
为更好的理解 innodb_index_stats,建一张测试表做说明:
CREATE TABLE t1 (
a INT, b INT, c INT, d INT, e INT, f INT,
PRIMARY KEY (a, b), KEY i1 (c, d), UNIQUE KEY i2uniq (e, f)
) ENGINE=INNODB;写入数据如下:
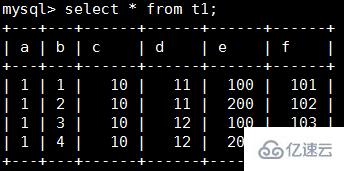
查看 t1 表的统计信息,需主要关注 stat_name 和 stat_value 字段
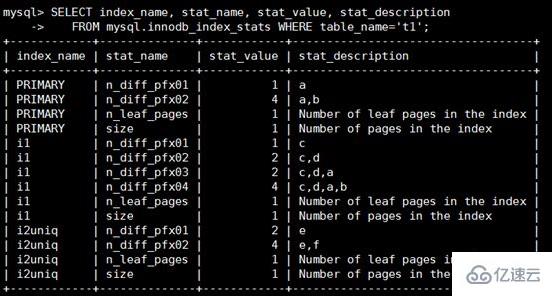
tat_name=size 时:stat_value 表示索引的页的数量
stat_name=n_leaf_pages 时:stat_value 表示叶子节点的数量
stat_name=n_diff_pfxNN 时:stat_value 表示索引字段上唯一值的数量,此处做一下具体说明:
1、n_diff_pfx01 表示索引第一列 distinct 之后的数量,如 PRIMARY 的 a 列,只有一个值 1,所以 index_name= PRIMARY and stat_name= n_diff_pfx01 时,stat_value=1。
2、n_diff_pfx02 表示索引前两列 distinct 之后的数量,如 i2uniq 的 e,f 列,有 4 个值,所以 index_name= i2uniq and stat_name= n_diff_pfx02 时,stat_value=4。
3、对于非唯一索引,会在原有列之后加上主键索引,如 index_name= i1 and stat_name= n_diff_pfx03,在原索引列 c,d 后加了主键列 a,(c,d,a) 的 distinct 结果为 2。
了解了 stat_name 和 stat_value 的具体含义,就可以协助我们排查 SQL 执行时为什么没有使用合适的索引,例如某个索引 n_diff_pfxNN 的 stat_value 远小于实际值,查询优化器认为该索引选择度较差,就有可能导致使用错误的索引。
三、统计信息不准确的处理
我们查看执行计划,发现未使用正确的索引,如果是 innodb_index_stats 中统计信息差别较大引起,可通过以下方式处理:
1、手动更新统计信息,注意执行过程中会加读锁:
ANALYZETABLE TABLE_NAME;
2、如果更新后统计信息仍不准确,可考虑增加表采样的数据页,两种方式可以修改:
a) 全局变量 INNODB_STATS_PERSISTENT_SAMPLE_PAGES,默认为 20;
b) 单个表可以指定该表的采样:
ALTER TABLE TABLE_NAME STATS_SAMPLE_PAGES=40;
经测试,此处 STATS_SAMPLE_PAGES 的最大值是 65535,超出会报错。
目前 MySQL 并没有提供直方图的功能,某些情况下(如数据分布不均)仅仅更新统计信息不一定能得到准确的执行计划,只能通过 index hint 的方式指定索引。新版本 8.0 会增加直方图功能,让我们期待 MySQL 越来越强大的功能吧!
以上是“MySQL 统计信息的存储有哪几种”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注丸趣 TV 行业资讯频道!
向 AI 问一下细节
