共计 2571 个字符,预计需要花费 7 分钟才能阅读完成。
自动写代码机器人,免费开通
这篇文章主要介绍了 redis 中热 key 问题的解决方法,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让丸趣 TV 小编带着大家一起了解一下。
正文
热 Key 问题
上面提到,所谓热 key 问题就是,突然有几十万的请求去访问 redis 上的某个特定 key。那么,这样会造成流量过于集中,达到物理网卡上限,从而导致这台 redis 的服务器宕机。
那接下来这个 key 的请求,就会直接怼到你的数据库上,导致你的服务不可用。
怎么发现热 key
方法一: 凭借业务经验,进行预估哪些是热 key
其实这个方法还是挺有可行性的。比如某商品在做秒杀,那这个商品的 key 就可以判断出是热 key。缺点很明显,并非所有业务都能预估出哪些 key 是热 key。
方法二: 在客户端进行收集
这个方式就是在操作 redis 之前,加入一行代码进行数据统计。那么这个数据统计的方式有很多种,也可以是给外部的通讯系统发送一个通知信息。缺点就是对客户端代码造成入侵。
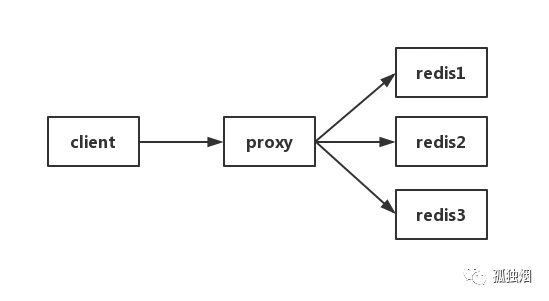
方法三: 在 Proxy 层做收集
有些集群架构是下面这样的,Proxy 可以是 Twemproxy,是统一的入口。可以在 Proxy 层做收集上报,但是缺点很明显,并非所有的 redis 集群架构都有 proxy。
方法四: 用 redis 自带命令
(1)monitor 命令,该命令可以实时抓取出 redis 服务器接收到的命令,然后写代码统计出热 key 是啥。当然,也有现成的分析工具可以给你使用,比如 redis-faina。但是该命令在高并发的条件下,有内存增暴增的隐患,还会降低 redis 的性能。
(2)hotkeys 参数,redis 4.0.3 提供了 redis-cli 的热点 key 发现功能,执行 redis-cli 时加上–hotkeys 选项即可。但是该参数在执行的时候,如果 key 比较多,执行起来比较慢。
方法五: 自己抓包评估
Redis 客户端使用 TCP 协议与服务端进行交互,通信协议采用的是 RESP。自己写程序监听端口,按照 RESP 协议规则解析数据,进行分析。缺点就是开发成本高,维护困难,有丢包可能性。
以上五种方案,各有优缺点。根据自己业务场景进行抉择即可。那么发现热 key 后,如何解决呢?
如何解决
目前业内的方案有两种
(1) 利用二级缓存
比如利用 ehcache,或者一个 HashMap 都可以。在你发现热 key 以后,把热 key 加载到系统的 JVM 中。
针对这种热 key 请求,会直接从 jvm 中取,而不会走到 redis 层。
假设此时有十万个针对同一个 key 的请求过来, 如果没有本地缓存,这十万个请求就直接怼到同一台 redis 上了。
现在假设,你的应用层有 50 台机器,OK,你也有 jvm 缓存了。这十万个请求平均分散开来,每个机器有 2000 个请求,会从 JVM 中取到 value 值,然后返回数据。避免了十万个请求怼到同一台 redis 上的情形。
(2) 备份热 key
这个方案也很简单。不要让 key 走到同一台 redis 上不就行了。我们把这个 key,在多个 redis 上都存一份不就好了。接下来,有热 key 请求进来的时候,我们就在有备份的 redis 上随机选取一台,进行访问取值,返回数据。
假设 redis 的集群数量为 N,步骤如下图所示
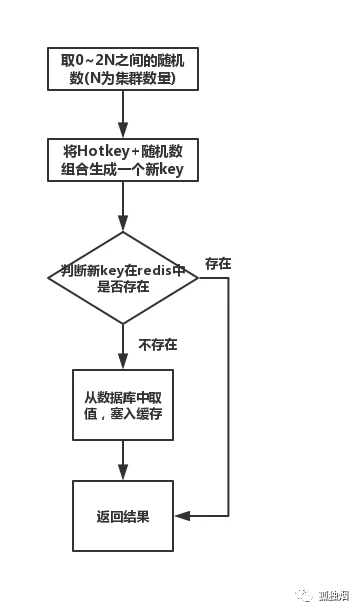
注: 不一定是 2N,你想取 3N,4N 都可以,看要求。
伪代码如下
const M = N * 2
// 生成随机数
random = GenRandom(0, M)
// 构造备份新 key
bakHotKey = hotKey + “_” + random
data = redis.GET(bakHotKey)
if data == NULL { data = GetFromDB()
redis.SET(bakHotKey, expireTime + GenRandom(0,5))
}
业内方案
OK,其实看完上面的内容,大家可能会有一个疑问。
烟哥,有办法在项目运行过程中,自动发现热 key,然后程序自动处理么?
嗯,好问题,那我们来讲讲业内怎么做的。其实只有两步
(1) 监控热 key
(2) 通知系统做处理
正巧,前几天有赞出了一篇《有赞透明多级缓存解决方案(TMC)》,里头也有提到热点 key 问题,我们刚好借此说明
(1) 监控热 key
在监控热 key 方面,有赞用的是方式二:在客户端进行收集。
在《有赞透明多级缓存解决方案(TMC)》中有一句话提到
TMC 对原生 jedis 包的 JedisPool 和 Jedis 类做了改造,在 JedisPool 初始化过程中集成 TMC“热点发现”+“本地缓存”功能 Hermes-SDK 包的初始化逻辑。
也就说人家改写了 jedis 原生的 jar 包,加入了 Hermes-SDK 包。
那 Hermes-SDK 包用来干嘛?
OK,就是做 热点发现 和 本地缓存。
从监控的角度看,该包对于 Jedis-Client 的每次 key 值访问请求,Hermes-SDK 都会通过其通信模块将 key 访问事件异步上报给 Hermes 服务端集群,以便其根据上报数据进行“热点探测”。
当然,这只是其中一种方式,有的公司在监控方面用的是方式五: 自己抓包评估
具体是这么做的,先利用 flink 搭建一套流式计算系统。然后自己写一个抓包程序抓 redis 监听端口的数据,抓到数据后往 kafka 里丢。
接下来,流式计算系统消费 kafka 里的数据,进行数据统计即可,也能达到监控热 key 的目的。
(2) 通知系统做处理
在这个角度,有赞用的是上面的解决方案一: 利用二级缓存进行处理。
有赞在监控到热 key 后,Hermes 服务端集群会通过各种手段通知各业务系统里的 Hermes-SDK,告诉他们: 老弟,这个 key 是热 key,记得做本地缓存。
于是 Hermes-SDK 就会将该 key 缓存在本地,对于后面的请求。Hermes-SDK 发现这个是一个热 key,直接从本地中拿,而不会去访问集群。
除了这种通知方式以外。我们也可以这么做,比如你的流式计算系统监控到热 key 了,往 zookeeper 里头的某个节点里写。然后你的业务系统监听该节点,发现节点数据变化了,就代表发现热 key。最后往本地缓存里写,也是可以的。
感谢你能够认真阅读完这篇文章,希望丸趣 TV 小编分享的“redis 中热 key 问题的解决方法”这篇文章对大家有帮助,同时也希望大家多多支持丸趣 TV,关注丸趣 TV 行业资讯频道,更多相关知识等着你来学习!
向 AI 问一下细节











