共计 17928 个字符,预计需要花费 45 分钟才能阅读完成。
自动写代码机器人,免费开通
这篇文章将为大家详细讲解有关 redis 与 memcached 的区别是什么,文章内容质量较高,因此丸趣 TV 小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
传统 MySQL+ Memcached 架构遇到的问题
实际 MySQL 是适合进行海量数据存储的,通过 Memcached 将热点数据加载到 cache,加速访问,很多公司都曾经使用过这样的架构,但随着业务数据量的不断增加,和访问量的持续增长,我们遇到了很多问题:
1.MySQL 需要不断进行拆库拆表,Memcached 也需不断跟着扩容,扩容和维护工作占据大量开发时间。
2.Memcached 与 MySQL 数据库数据一致性问题。
3.Memcached 数据命中率低或 down 机,大量访问直接穿透到 DB,MySQL 无法支撑。
4. 跨机房 cache 同步问题。
众多 NoSQL 百花齐放,如何选择
最近几年,业界不断涌现出很多各种各样的 NoSQL 产品,那么如何才能正确地使用好这些产品,最大化地发挥其长处,是我们需要深入研究和思考的问题,实际归根结底最重要的是了解这些产品的定位,并且了解到每款产品的 tradeoffs,在实际应用中做到扬长避短,总体上这些 NoSQL 主要用于解决以下几种问题
1. 少量数据存储,高速读写访问。此类产品通过数据全部 in-momery 的方式来保证高速访问,同时提供数据落地的功能,实际这正是 Redis 最主要的适用场景。
2. 海量数据存储,分布式系统支持,数据一致性保证,方便的集群节点添加 / 删除。
3. 这方面最具代表性的是 dynamo 和 bigtable 2 篇论文所阐述的思路。前者是一个完全无中心的设计,节点之间通过 gossip 方式传递集群信息,数据保证最终一致性,后者是一个中心化的方案设计,通过类似一个分布式锁服务来保证强一致性, 数据写入先写内存和 redo log,然后定期 compat 归并到磁盘上,将随机写优化为顺序写,提高写入性能。
4.Schema free,auto-sharding 等。比如目前常见的一些文档数据库都是支持 schema-free 的,直接存储 json 格式数据,并且支持 auto-sharding 等功能,比如 mongodb。
面对这些不同类型的 NoSQL 产品, 我们需要根据我们的业务场景选择最合适的产品。
Redis 适用场景,如何正确的使用
前面已经分析过,Redis 最适合所有数据 in-momory 的场景,虽然 Redis 也提供持久化功能,但实际更多的是一个 disk-backed 的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎 Redis 更像一个加强版的 Memcached,那么何时使用 Memcached, 何时使用 Redis 呢?
如果简单地比较 Redis 与 Memcached 的区别,大多数都会得到以下观点:
1 Redis 不仅仅支持简单的 k / v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。
2 Redis 支持数据的备份,即 master-slave 模式的数据备份。
3 Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
抛开这些,可以深入到 Redis 内部构造去观察更加本质的区别,理解 Redis 的设计。
在 Redis 中,并不是所有的数据都一直存储在内存中的。这是和 Memcached 相比一个最大的区别。Redis 只会缓存所有的 key 的信息,如果 Redis 发现内存的使用量超过了某一个阀值,将触发 swap 的操作,Redis 根据“swappability = age*log(size_in_memory)”计 算出哪些 key 对应的 value 需要 swap 到磁盘。然后再将这些 key 对应的 value 持久化到磁盘中,同时在内存中清除。这种特性使得 Redis 可以 保持超过其机器本身内存大小的数据。当然,机器本身的内存必须要能够保持所有的 key,毕竟这些数据是不会进行 swap 操作的。同时由于 Redis 将内存 中的数据 swap 到磁盘中的时候,提供服务的主线程和进行 swap 操作的子线程会共享这部分内存,所以如果更新需要 swap 的数据,Redis 将阻塞这个 操作,直到子线程完成 swap 操作后才可以进行修改。
使用 Redis 特有内存模型前后的情况对比:
VM off: 300k keys, 4096 bytes values: 1.3G used
VM on: 300k keys, 4096 bytes values: 73M used
VM off: 1 million keys, 256 bytes values: 430.12M used
VM on: 1 million keys, 256 bytes values: 160.09M used
VM on: 1 million keys, values as large as you want, still: 160.09M used当 从 Redis 中读取数据的时候,如果读取的 key 对应的 value 不在内存中,那么 Redis 就需要从 swap 文件中加载相应数据,然后再返回给请求方。这里就存在一个 I / O 线程池的问题。在默认的情况下,Redis 会出现阻塞,即完成所有的 swap 文件加载后才会相应。这种策略在客户端的数量较小,进行 批量操作的时候比较合适。但是如果将 Redis 应用在一个大型的网站应用程序中,这显然是无法满足大并发的情况的。所以 Redis 运行我们设置 I / O 线程 池的大小,对需要从 swap 文件中加载相应数据的读取请求进行并发操作,减少阻塞的时间。
如果希望在海量数据的环境中使用好 Redis,我相信理解 Redis 的内存设计和阻塞的情况是不可缺少的。
补充的知识点:
memcached 和 redis 的比较
1 网络 IO 模型
Memcached 是多线程,非阻塞 IO 复用的网络模型,分为监听主线程和 worker 子线程,监听线程监听网络连接,接受请求后,将连接描述字 pipe 传递给 worker 线程,进行读写 IO, 网络层使用 libevent 封装的事件库,多线程模型可以发挥多核作用,但是引入了 cache coherency 和锁的问题,比如,Memcached 最常用的 stats 命令,实际 Memcached 所有操作都要对这个全局变量加锁,进行计数等工作,带来了性能损耗。
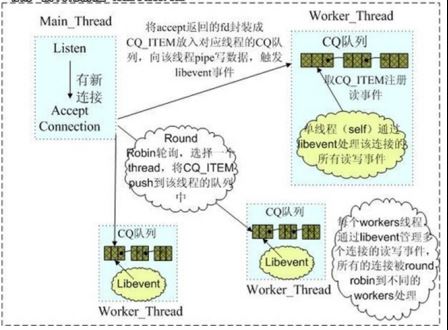
(Memcached 网络 IO 模型)
Redis 使用单线程的 IO 复用模型,自己封装了一个简单的 AeEvent 事件处理框架,主要实现了 epoll、kqueue 和 select,对于单纯只有 IO 操作来说,单线程可以将速度优势发挥到最大,但是 Redis 也提供了一些简单的计算功能,比如排序、聚合等,对于这些操作,单线程模型实际会严重影响整体吞吐量,CPU 计算过程中,整个 IO 调度都是被阻塞住的。
2. 内存管理方面
Memcached 使用预分配的内存池的方式,使用 slab 和大小不同的 chunk 来管理内存,Item 根据大小选择合适的 chunk 存储,内存池的方式可以省去申请 / 释放内存的开销,并且能减小内存碎片产生,但这种方式也会带来一定程度上的空间浪费,并且在内存仍然有很大空间时,新的数据也可能会被剔除,原因可以参考 Timyang 的文章:http://timyang.net/data/Memcached-lru-evictions/
Redis 使用现场申请内存的方式来存储数据,并且很少使用 free-list 等方式来优化内存分配,会在一定程度上存在内存碎片,Redis 跟据存储命令参数,会把带过期时间的数据单独存放在一起,并把它们称为临时数据,非临时数据是永远不会被剔除的,即便物理内存不够,导致 swap 也不会剔除任何非临时数据(但会尝试剔除部分临时数据),这点上 Redis 更适合作为存储而不是 cache。
3. 数据一致性问题
Memcached 提供了 cas 命令,可以保证多个并发访问操作同一份数据的一致性问题。Redis 没有提供 cas 命令,并不能保证这点,不过 Redis 提供了事务的功能,可以保证一串 命令的原子性,中间不会被任何操作打断。
4. 存储方式及其它方面
Memcached 基本只支持简单的 key-value 存储,不支持枚举,不支持持久化和复制等功能
Redis 除 key/value 之外,还支持 list,set,sorted set,hash 等众多数据结构,提供了 KEYS
进行枚举操作,但不能在线上使用,如果需要枚举线上数据,Redis 提供了工具可以直接扫描其 dump 文件,枚举出所有数据,Redis 还同时提供了持久化和复制等功能。
5. 关于不同语言的客户端支持
在不同语言的客户端方面,Memcached 和 Redis 都有丰富的第三方客户端可供选择,不过因为 Memcached 发展的时间更久一些,目前看在客户端支持方面,Memcached 的很多客户端更加成熟稳定,而 Redis 由于其协议本身就比 Memcached 复杂,加上作者不断增加新的功能等,对应第三方客户端跟进速度可能会赶不上,有时可能需要自己在第三方客户端基础上做些修改才能更好的使用。
根据以上比较不难看出,当我们不希望数据被踢出,或者需要除 key/value 之外的更多数据类型时,或者需要落地功能时,使用 Redis 比使用 Memcached 更合适。
关于 Redis 的一些周边功能
Redis 除了作为存储之外还提供了一些其它方面的功能,比如聚合计算、pubsub、scripting 等,对于此类功能需要了解其实现原理,清楚地了解到它的局限性后,才能正确的使用,比如 pubsub 功能,这个实际是没有任何持久化支持的,消费方连接闪断或重连之间过来的消息是会全部丢失的,又比如聚合计算和 scripting 等功能受 Redis 单线程模型所限,是不可能达到很高的吞吐量的,需要谨慎使用。
总的来说 Redis 作者是一位非常勤奋的开发者,可以经常看到作者在尝试着各种不同的新鲜想法和思路,针对这些方面的功能就要求我们需要深入了解后再使用。
总结:
1.Redis 使用最佳方式是全部数据 in-memory。
2.Redis 更多场景是作为 Memcached 的替代者来使用。
3. 当需要除 key/value 之外的更多数据类型支持时,使用 Redis 更合适。
4. 当存储的数据不能被剔除时,使用 Redis 更合适。
谈谈 Memcached 与 Redis
1. Memcached 简介
Memcached 是以 LiveJurnal 旗下 Danga Interactive 公司的 Bard Fitzpatric 为首开发的高性能分布式内存缓存服务器。其本质上就是一个内存 key-value 数据库,但是不支持数据的持久化,服务器关闭之后数据全部丢失。Memcached 使用 C 语言开发,在大多数像 Linux、BSD 和 Solaris 等 POSIX 系统上,只要安装了 libevent 即可使用。在 Windows 下,它也有一个可用的非官方版本(http://code.jellycan.com/memcached/)。Memcached 的客户端软件实现非常多,包括 C /C++, PHP, Java, Python, Ruby, Perl, Erlang, Lua 等。当前 Memcached 使用广泛,除了 LiveJournal 以外还有 Wikipedia、Flickr、Twitter、Youtube 和 WordPress 等。
在 Window 系统下,Memcached 的安装非常方便,只需从以上给出的地址下载可执行软件然后运行 memcached.exe –d install 即可完成安装。在 Linux 等系统下,我们首先需要安装 libevent,然后从获取源码,make make install 即可。默认情况下,Memcached 的服务器启动程序会安装到 /usr/local/bin 目录下。在启动 Memcached 时,我们可以为其配置不同的启动参数。
1.1 Memcache 配置
Memcached 服务器在启动时需要对关键的参数进行配置,下面我们就看一看 Memcached 在启动时需要设定哪些关键参数以及这些参数的作用。
1)-p num Memcached 的 TCP 监听端口,缺省配置为 11211;
2)-U num Memcached 的 UDP 监听端口,缺省配置为 11211,为 0 时表示关闭 UDP 监听;
3)-s file Memcached 监听的 UNIX 套接字路径;
4)-a mask 访问 UNIX 套接字的八进制掩码,缺省配置为 0700;
5)-l addr 监听的服务器 IP 地址,默认为所有网卡;
6)-d 为 Memcached 服务器启动守护进程;
7)-r 最大 core 文件大小;
8)-u username 运行 Memcached 的用户,如果当前为 root 的话需要使用此参数指定用户;
9)-m num 分配给 Memcached 使用的内存数量,单位是 MB;
10)-M 指示 Memcached 在内存用光的时候返回错误而不是使用 LRU 算法移除数据记录;
11)-c num 最大并发连数,缺省配置为 1024;
12)-v –vv –vvv 设定服务器端打印的消息的详细程度,其中 - v 仅打印错误和警告信息,-vv 在 - v 的基础上还会打印客户端的命令和相应,-vvv 在 -vv 的基础上还会打印内存状态转换信息;
13)-f factor 用于设置 chunk 大小的递增因子;
14)-n bytes 最小的 chunk 大小,缺省配置为 48 个字节;
15)-t num Memcached 服务器使用的线程数,缺省配置为 4 个;
16)-L 尝试使用大内存页;
17)-R 每个事件的最大请求数,缺省配置为 20 个;
18)-C 禁用 CAS,CAS 模式会带来 8 个字节的冗余;
2. Redis 简介
Redis 是一个开源的 key-value 存储系统。与 Memcached 类似,Redis 将大部分数据存储在内存中,支持的数据类型包括:字符串、哈希表、链表、集合、有序集合以及基于这些数据类型的相关操作。Redis 使用 C 语言开发,在大多数像 Linux、BSD 和 Solaris 等 POSIX 系统上无需任何外部依赖就可以使用。Redis 支持的客户端语言也非常丰富,常用的计算机语言如 C、C#、C++、Object-C、PHP、Python、Java、Perl、Lua、Erlang 等均有可用的客户端来访问 Redis 服务器。当前 Redis 的应用已经非常广泛,国内像新浪、淘宝,国外像 Flickr、Github 等均在使用 Redis 的缓存服务。
Redis 的安装非常方便,只需从 http://redis.io/download 获取源码,然后 make make install 即可。默认情况下,Redis 的服务器启动程序和客户端程序会安装到 /usr/local/bin 目录下。在启动 Redis 服务器时,我们需要为其指定一个配置文件,缺省情况下配置文件在 Redis 的源码目录下,文件名为 redis.conf。
2.1 Redis 配置文件
为了对 Redis 的系统实现有一个直接的认识,我们首先来看一下 Redis 的配置文件中定义了哪些主要参数以及这些参数的作用。
1)daemonize no 默认情况下,redis 不是在后台运行的。如果需要在后台运行,把该项的值更改为 yes;
2)pidfile /var/run/redis.pid 当 Redis 在后台运行的时候,Redis 默认会把 pid 文件放在 /var/run/redis.pid,你可以配置到其他地址。当运行多个 redis 服务时,需要指定不同的 pid 文件和端口;
3)port 6379 指定 redis 运行的端口,默认是 6379;
4)bind 127.0.0.1 指定 redis 只接收来自于该 IP 地址的请求,如果不进行设置,那么将处理所有请求。在生产环境中最好设置该项;
5)loglevel debug 指定日志记录级别,其中 Redis 总共支持四个级别:debug、verbose、notice、warning,默认为 verbose。debug 表示记录很多信息,用于开发和测试。verbose 表示记录有用的信息,但不像 debug 会记录那么多。notice 表示普通的 verbose,常用于生产环境。
warning 表示只有非常重要或者严重的信息会记录到日志;
6)logfile /var/log/redis/redis.log 配置 log 文件地址,默认值为 stdout。若后台模式会输出到 /dev/null;
7)databases 16 可用数据库数,默认值为 16,默认数据库为 0,数据库范围在 0 -(database-1)之间;
8)save 900 1 保存数据到磁盘,格式为 save seconds changes,指出在多长时间内,有多少次更新操作,就将数据同步到数据文件 rdb。相当于条件触发抓取快照,这个可以多个条件配合。save 900 1 就表示 900 秒内至少有 1 个 key 被改变就保存数据到磁盘;
9)rdbcompression yes 存储至本地数据库时(持久化到 rdb 文件)是否压缩数据,默认为 yes;
10)dbfilename dump.rdb 本地持久化数据库文件名,默认值为 dump.rdb;
11)dir ./ 工作目录,数据库镜像备份的文件放置的路径。这里的路径跟文件名要分开配置是因为 redis 在进行备份时,先会将当前数据库的状态写入到一个临时文件中,等备份完成时,再把该临时文件替换为上面所指定的文件。而这里的临时文件和上面所配置的备份文件都会放在这个指定的路径当中,AOF 文件也会存放在这个目录下面。注意这里必须指定一个目录而不是文件;
12)slaveof masterip masterport 主从复制,设置该数据库为其他数据库的从数据库。设置当本机为 slave 服务时,设置 master 服务的 IP 地址及端口。在 Redis 启动时,它会自动从 master 进行数据同步;
13)masterauth master-password 当 master 服务设置了密码保护时(用 requirepass 制定的密码)slave 服务连接 master 的密码;
14)slave-serve-stale-data yes 当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:如果 slave-serve-stale-data 设置为 yes(默认设置),从库会继续相应客户端的请求。如果 slave-serve-stale-data 是指为 no,除去 INFO 和 SLAVOF 命令之外的任何请求都会返回一个错误 SYNC with master in progress;
15)repl-ping-slave-period 10 从库会按照一个时间间隔向主库发送 PING,可以通过 repl-ping-slave-period 设置这个时间间隔,默认是 10 秒;
16)repl-timeout 60 设置主库批量数据传输时间或者 ping 回复时间间隔,默认值是 60 秒,一定要确保 repl-timeout 大于 repl-ping-slave-period;
17)requirepass foobared 设置客户端连接后进行任何其他指定前需要使用的密码。因为 redis 速度相当快,所以在一台比较好的服务器下,一个外部的用户可以在一秒钟进行 150K 次的密码尝试,这意味着你需要指定非常强大的密码来防止暴力破解;
18)rename-command CONFIG 命令重命名,在一个共享环境下可以重命名相对危险的命令,比如把 CONFIG 重名为一个不容易猜测的字符:# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52。如果想删除一个命令,直接把它重命名为一个空字符 即可:rename-command CONFIG;
19)maxclients 128 设置同一时间最大客户端连接数,默认无限制。Redis 可以同时打开的客户端连接数为 Redis 进程可以打开的最大文件描述符数。如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis 会关闭新的连接并向客户端返回 max number of clients
reached 错误信息;
20)maxmemory bytes 指定 Redis 最大内存限制。Redis 在启动时会把数据加载到内存中,达到最大内存后,Redis 会先尝试清除已到期或即将到期的 Key,Redis 同时也会移除空的 list 对象。当此方法处理后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。注意:Redis 新的 vm 机制,会把 Key 存放内存,Value 会存放在 swap 区;
21)maxmemory-policy volatile-lru 当内存达到最大值的时候 Redis 会选择删除哪些数据呢?有五种方式可供选择:volatile-lru 代表利用 LRU 算法移除设置过过期时间的 key (LRU: 最近使用 Least Recently Used),allkeys-lru 代表利用 LRU 算法移除任何 key,volatile-random 代表移除设置过过期时间的随机 key,allkeys_random 代表移除一个随机的 key,volatile-ttl 代表移除即将过期的 key(minor TTL),noeviction 代表不移除任何 key,只是返回一个写错误。
注意:对于上面的策略,如果没有合适的 key 可以移除,写的时候 Redis 会返回一个错误;
22)appendonly no 默认情况下,redis 会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频繁。如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失,所以 redis 提供了另外一种更加高效的数据库备份及灾难恢复方式。开启 append only 模式之后,redis 会把所接收到的每一次写操作请求都追加到 appendonly.aof 文件中。当 redis 重新启动时,会从该文件恢复出之前的状态,但是这样会造成 appendonly.aof 文件过大,所以 redis 还支持了 BGREWRITEAOF 指令对 appendonly.aof 进行重新整理,你可以同时
开启 asynchronous dumps 和 AOF;
23)appendfilename appendonly.aof AOF 文件名称, 默认为 appendonly.aof
24)appendfsync everysec Redis 支持三种同步 AOF 文件的策略: no 代表不进行同步,系统去操作,always 代表每次有写操作都进行同步,everysec 代表对写操作进行累积,每秒同步一次,默认是 everysec,按照速度和安全折中这是最好的。
25)slowlog-log-slower-than 10000 记录超过特定执行时间的命令。执行时间不包括 I / O 计算,比如连接客户端,返回结果等,只是命令执行时间。可以通过两个参数设置 slow log:一个是告诉 Redis 执行超过多少时间被记录的参数 slowlog-log-slower-than(微妙),另一个是 slow
log 的长度。当一个新命令被记录的时候最早的命令将被从队列中移除,下面的时间以微妙微单位,因此 1000000 代表一分钟。注意制定一个负数将关闭慢日志,而设置为 0 将强制每个命令都会记录;
26)hash-max-zipmap-entries 512 hash-max-zipmap-value 64 当 hash 中包含超过指定元素个数并且最大的元素没有超过临界时,hash 将以一种特殊的编码方式(大大减少内存使用)来存储,这里可以设置这两个临界值。Redis Hash 对应 Value 内部实际就是一个 HashMap,实际这里会有 2 种不同实现。这个 Hash 的成员比较少时 Redis 为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的 HashMap 结构,对应的 value redisObject 的 encoding 为 zipmap。当成员数量增大时会自动转成真正的 HashMap,此时 encoding 为 ht;
27)list-max-ziplist-entries 512 list 数据类型多少节点以下会采用去指针的紧凑存储格式;
28)list-max-ziplist-value 64 数据类型节点值大小小于多少字节会采用紧凑存储格式;
29)set-max-intset-entries 512 set 数据类型内部数据如果全部是数值型,且包含多少节点以下会采用紧凑格式存储;
30)zset-max-ziplist-entries 128 zsort 数据类型多少节点以下会采用去指针的紧凑存储格式;
31)zset-max-ziplist-value 64 zsort 数据类型节点值大小小于多少字节会采用紧凑存储格式。
32)activerehashing yes Redis 将在每 100 毫秒时使用 1 毫秒的 CPU 时间来对 redis 的 hash 表进行重新 hash,可以降低内存的使用。当你的使用场景中,有非常严格的实时性需要,不能够接受 Redis 时不时的对请求有 2 毫秒的延迟的话,把这项配置为 no。如果没有这么严格的实时性要求,可以设置为 yes,以便能够尽可能快的释放内存;
Redis 的常用数据类型
与 Memcached 仅支持简单的 key-value 结构的数据记录不同,Redis 支持的数据类型要丰富得多。最为常用的数据类型主要由五种:String、Hash、List、Set 和 Sorted Set。在具体描述这几种数据类型之前,我们先通过一张图来了解下 Redis 内部内存管理中是如何描述这些不同数据类型的。
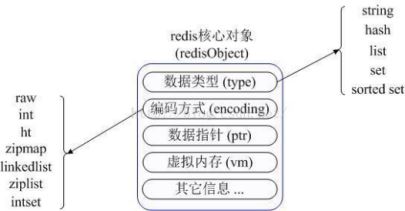
图 1 Redis 对象
Redis 内部使用一个 redisObject 对象来表示所有的 key 和 value。redisObject 最主要的信息如图 1 所示:type 代表一个 value 对象具体是何种数据类型,encoding 是不同数据类型在 redis 内部的存储方式,比如:type=string 代表 value 存储的是一个普通字符串,那么对应的 encoding 可以是 raw 或者是 int,如果是 int 则代表实际 redis 内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如: 123 456 这样的字符串。这里需要特殊说明一下 vm 字段,只有打开了 Redis 的虚拟内存功能,此字段才会真正的分配内存,该功能默认是关闭状态的。通过 Figure1 我们可以发现 Redis 使用 redisObject 来表示所有的 key/value 数据是比较浪费内存的,当然这些内存管理成本的付出主要也是为了给 Redis 不同数据类型提供一个统一的管理接口,实际作者也提供了多种方法帮助我们尽量节省内存使用。下面我们先来逐一的分析下这五种数据类型的使用和内部实现方式。
1)String
常用命令:set/get/decr/incr/mget 等;
应用场景:String 是最常用的一种数据类型,普通的 key/value 存储都可以归为此类;
实现方式:String 在 redis 内部存储默认就是一个字符串,被 redisObject 所引用,当遇到 incr、decr 等操作时会转成数值型进行计算,此时 redisObject 的 encoding 字段为 int。
2)Hash
常用命令:hget/hset/hgetall 等
应用场景:我们要存储一个用户信息对象数据,其中包括用户 ID、用户姓名、年龄和生日,通过用户 ID 我们希望获取该用户的姓名或者年龄或者生日;
实现方式:Redis 的 Hash 实际是内部存储的 Value 为一个 HashMap,并提供了直接存取这个 Map 成员的接口。如图 2 所示,Key 是用户 ID, value 是一个 Map。这个 Map 的 key 是成员的属性名,value 是属性值。这样对数据的修改和存取都可以直接通过其内部 Map 的 Key(Redis 里称内部 Map 的 key 为 field), 也就是通过 key(用户 ID) + field(属性标签) 就可以操作对应属性数据。当前 HashMap 的实现有两种方式:当 HashMap 的成员比较少时 Redis 为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的 HashMap 结构,这时对应的 value 的 redisObject 的 encoding 为 zipmap,当成员数量增大时会自动转成真正的 HashMap, 此时 encoding 为 ht。
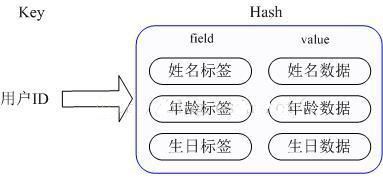
图 2 Redis 的 Hash 数据类型
3)List
常用命令:lpush/rpush/lpop/rpop/lrange 等;
应用场景:Redis list 的应用场景非常多,也是 Redis 最重要的数据结构之一,比如 twitter 的关注列表,粉丝列表等都可以用 Redis 的 list 结构来实现;
实现方式:Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
4)Set
常用命令:sadd/spop/smembers/sunion 等;
应用场景:Redis set 对外提供的功能与 list 类似是一个列表的功能,特殊之处在于 set 是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的;
实现方式:set 的内部实现是一个 value 永远为 null 的 HashMap,实际就是通过计算 hash 的方式来快速排重的,这也是 set 能提供判断一个成员是否在集合内的原因。
5)Sorted Set
常用命令:zadd/zrange/zrem/zcard 等;
应用场景:Redis sorted set 的使用场景与 set 类似,区别是 set 不是自动有序的,而 sorted set 可以通过用户额外提供一个优先级 (score) 的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择 sorted set 数据结构,比如
twitter 的 public timeline 可以以发表时间作为 score 来存储,这样获取时就是自动按时间排好序的。
实现方式:Redis sorted set 的内部使用 HashMap 和跳跃表 (SkipList) 来保证数据的存储和有序,HashMap 里放的是成员到 score 的映射,而跳跃表里存放的是所有的成员,排序依据是 HashMap 里存的 score, 使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
2.3 Redis 的持久化
Redis 虽然是基于内存的存储系统,但是它本身是支持内存数据的持久化的,而且提供两种主要的持久化策略:RDB 快照和 AOF 日志。我们会在下文分别介绍这两种不同的持久化策略。
2.3.1 Redis 的 AOF 日志
Redis 支持将当前数据的快照存成一个数据文件的持久化机制,即 RDB 快照。这种方法是非常好理解的,但是一个持续写入的数据库如何生成快照呢?Redis 借助了 fork 命令的 copy on write 机制。在生成快照时,将当前进程 fork 出一个子进程,然后在子进程中循环所有的数据,将数据
写成为 RDB 文件。
我们可以通过 Redis 的 save 指令来配置 RDB 快照生成的时机,比如你可以配置当 10 分钟以内有 100 次写入就生成快照,也可以配置当 1 小时内有 1000 次写入就生成快照,也可以多个规则一起实施。这些规则的定义就在 Redis 的配置文件中,你也可以通过 Redis 的 CONFIG SET 命令在 Redis 运
行时设置规则,不需要重启 Redis。
Redis 的 RDB 文件不会坏掉,因为其写操作是在一个新进程中进行的,当生成一个新的 RDB 文件时,Redis 生成的子进程会先将数据写到一个临时文件中,然后通过原子性 rename 系统调用将临时文件重命名为 RDB 文件,这样在任何时候出现故障,Redis 的 RDB 文件都总是可用的。同时,Redis 的 RDB 文件也是 Redis 主从同步内部实现中的一环。
但是,我们可以很明显的看到,RDB 有他的不足,就是一旦数据库出现问题,那么我们的 RDB 文件中保存的数据并不是全新的,从上次 RDB 文件生成到 Redis 停机这段时间的数据全部丢掉了。在某些业务下,这是可以忍受的,我们也推荐这些业务使用 RDB 的方式进行持久化,因为开启 RDB
的代价并不高。但是对于另外一些对数据安全性要求极高的应用,无法容忍数据丢失的应用,RDB 就无能为力了,所以 Redis 引入了另一个重要的持久化机制:AOF 日志。
Redis 的 AOF 日志
AOF 日志的全称是 append only file,从名字上我们就能看出来,它是一个追加写入的日志文件。与一般数据库的 binlog 不同的是,AOF 文件是可识别的纯文本,它的内容就是一个个的 Redis 标准命令。当然,并不是发送发 Redis 的所有命令都要记录到 AOF 日志里面,只有那些会导致数据发生修改的命令才会追加到 AOF 文件。那么每一条修改数据的命令都生成一条日志,那么 AOF 文件是不是会很大?答案是肯定的,AOF 文件会越来越大,所以 Redis 又提供了一个功能,叫做 AOF rewrite。其功能就是重新生成一份 AOF 文件,新的 AOF 文件中一条记录的操作只会有一次,而不像一份老文件那样,可能记录了对同一个值的多次操作。其生成过程和 RDB 类似,也是 fork 一个进程,直接遍历数据,写入新的 AOF 临时文件。在写入新文件的过程中,所有的写操作日志还是会写到原来老的 AOF 文件中,同时还会记录在内存缓冲区中。当重完操作完成后,会将所有缓冲区中的日志一次性写入到临时文件中。然后调用原子性的 rename 命令用新的 AOF 文件取代老的 AOF 文件。
AOF 是一个写文件操作,其目的是将操作日志写到磁盘上,所以它也同样会遇到我们上面说的写操作的 5 个流程。那么写 AOF 的操作安全性又有多高呢。实际上这是可以设置的,在 Redis 中对 AOF 调用 write(2)写入后,何时再调用 fsync 将其写到磁盘上,通过 appendfsync 选项来控制,下面 appendfsync 的三个设置项,安全强度逐渐变强。
1)appendfsync no
当设置 appendfsync 为 no 的时候,Redis 不会主动调用 fsync 去将 AOF 日志内容同步到磁盘,所以这一切就完全依赖于操作系统的调试了。对大多数 Linux 操作系统,是每 30 秒进行一次 fsync,将缓冲区中的数据写到磁盘上。
2)appendfsync everysec
当设置 appendfsync 为 everysec 的时候,Redis 会默认每隔一秒进行一次 fsync 调用,将缓冲区中的数据写到磁盘。但是当这一次的 fsync 调用时长超过 1 秒时。Redis 会采取延迟 fsync 的策略,再等一秒钟。也就是在两秒后再进行 fsync,这一次的 fsync 就不管会执行多长时间都会进行。这时候由于在 fsync 时文件描述符会被阻塞,所以当前的写操作就会阻塞。所以结论就是,在绝大多数情况下,Redis 会每隔一秒进行一次 fsync。在最坏的情况下,两秒钟会进行一次 fsync 操作。这一操作在大多数数据库系统中被称为 group commit,就是组合多次写操作的数据,一次性将日志写到磁盘。
3)appednfsync always
当设置 appendfsync 为 always 时,每一次写操作都会调用一次 fsync,这时数据是最安全的,当然,由于每次都会执行 fsync,所以其性能也会受到影响。
3. Memcached 和 Redis 关键技术对比
作为内存数据缓冲系统,Memcached 和 Redis 均具有很高的性能,但是两者在关键实现技术上具有很大差异,这种差异决定了两者具有不同的特点和不同的适用条件。下面我们会对两者的关键技术进行一些对比,以此来揭示两者的差异。
Memcached 和 Redis 的内存管理机制对比
对于像 Redis 和 Memcached 这种基于内存的数据库系统来说,内存管理的效率高低是影响系统性能的关键因素。传统 C 语言中的 malloc/free 函数是最常用的分配和释放内存的方法,但是这种方法存在着很大的缺陷:首先,对于开发人员来说不匹配的 malloc 和 free 容易造成内存泄露;其次,频繁调用会造成大量内存碎片无法回收重新利用,降低内存利用率;最后,作为系统调用,其系统开销远远大于一般函数调用。所以,为了提高内存的管理效率,高效的内存管理方案都不会直接使用 malloc/free 调用。Redis 和 Memcached 均使用了自身设计的内存管理机制,但是实现方法存在很大的差异,下面将会对两者的内存管理机制分别进行介绍。
Memcached 的内存管理机制
Memcached 默认使用 Slab Allocation 机制管理内存,其主要思想是按照预先规定的大小,将分配的内存分割成特定长度的块以存储相应长度的 key-value 数据记录,以完全解决内存碎片问题。Slab Allocation 机制只为存储外部数据而设计,也就是说所有的 key-value 数据都存储在 Slab Allocation 系统里,而 Memcached 的其它内存请求则通过普通的 malloc/free 来申请,因为这些请求的数量和频率决定了它们不会对整个系统的性能造成影响
Slab Allocation 的原理相当简单。如图 3 所示,它首先从操作系统申请一大块内存,并将其分割成各种尺寸的块 Chunk,并把尺寸相同的块分成组 Slab Class。其中,Chunk 就是用来存储 key-value 数据的最小单位。每个 Slab Class 的大小,可以在 Memcached 启动的时候通过制定 Growth Factor 来控制。假定 Figure 1 中 Growth Factor 的取值为 1.25,所以如果第一组 Chunk 的大小为 88 个字节,第二组 Chunk 的大小就为 112 个字节,依此类推。
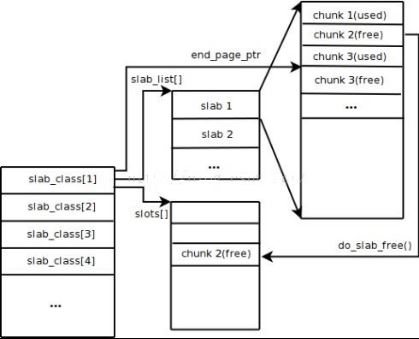
图 3 Memcached 内存管理架构
当 Memcached 接收到客户端发送过来的数据时首先会根据收到数据的大小选择一个最合适的 Slab Class,然后通过查询 Memcached 保存着的该 Slab Class 内空闲 Chunk 的列表就可以找到一个可用于存储数据的 Chunk。当一条数据库过期或者丢弃时,该记录所占用的 Chunk 就可以回收,重新添加到空闲列表中。从以上过程我们可以看出 Memcached 的内存管理制效率高,而且不会造成内存碎片,但是它最大的缺点就是会导致空间浪费。因为每个 Chunk 都分配了特定长度的内存空间,所以变长数据无法充分利用这些空间。如图 4 所示,将 100 个字节的数据缓存到 128 个字节的 Chunk 中,剩余的 28 个字节就浪费掉了。

图 4 Memcached 的存储空间浪费
Redis 的内存管理机制
Redis 的内存管理主要通过源码中 zmalloc.h 和 zmalloc.c 两个文件来实现的。Redis 为了方便内存的管理,在分配一块内存之后,会将这块内存的大小存入内存块的头部。如图 5 所示,real_ptr 是 redis 调用 malloc 后返回的指针。redis 将内存块的大小 size 存入头部,size 所占据的内存大小是已知的,为 size_t 类型的长度,然后返回 ret_ptr。当需要释放内存的时候,ret_ptr 被传给内存管理程序。通过 ret_ptr,程序可以很容易的算出 real_ptr 的值,然后将 real_ptr 传给 free 释放内存。

图 5 Redis 块分配
Redis 通过定义一个数组来记录所有的内存分配情况,这个数组的长度为 ZMALLOC_MAX_ALLOC_STAT。数组的每一个元素代表当前程序所分配的内存块的个数,且内存块的大小为该元素的下标。在源码中,这个数组为 zmalloc_allocations。zmalloc_allocations[16]代表已经分配的长度为 16bytes 的内存块的个数。zmalloc.c 中有一个静态变量 used_memory 用来记录当前分配的内存总大小。所以,总的来看,Redis 采用的是包装的 mallc/free,相较于 Memcached 的内存管理方法来说,要简单很多。
Redis 和 Memcached 的集群实现机制对比
Memcached 是全内存的数据缓冲系统,Redis 虽然支持数据的持久化,但是全内存毕竟才是其高性能的本质。作为基于内存的存储系统来说,机器物理内存的大小就是系统能够容纳的最大数据量。如果需要处理的数据量超过了单台机器的物理内存大小,就需要构建分布式集群来扩展存储能力。
Memcached 的分布式存储
Memcached 本身并不支持分布式,因此只能在客户端通过像一致性哈希这样的分布式算法来实现 Memcached 的分布式存储。图 6 给出了 Memcached 的分布式存储实现架构。当客户端向 Memcached 集群发送数据之前,首先会通过内置的分布式算法计算出该条数据的目标节点,然后数据会直接发送到该节点上存储。但客户端查询数据时,同样要计算出查询数据所在的节点,然后直接向该节点发送查询请求以获取数据。
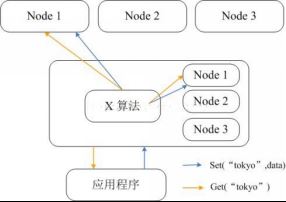
图 6 Memcached 客户端分布式存储实现
Redis 的分布式存储
相较于 Memcached 只能采用客户端实现分布式存储,Redis 更偏向于在服务器端构建分布式存储。尽管 Redis 当前已经发布的稳定版本还没有添加分布式存储功能,但 Redis 开发版中已经具备了 Redis Cluster 的基本功能。预计在 2.6 版本之后,Redis 就会发布完全支持分布式的稳定版本,时间不晚于 2012 年底。下面我们会根据开发版中的实现,简单介绍一下 Redis Cluster 的核心思想。
Redis Cluster 是一个实现了分布式且允许单点故障的 Redis 高级版本,它没有中心节点,具有线性可伸缩的功能。图 7 给出 Redis Cluster 的分布式存储架构,其中节点与节点之间通过二进制协议进行通信,节点与客户端之间通过 ascii 协议进行通信。在数据的放置策略上,Redis Cluster 将整个 key 的数值域分成 4096 个哈希槽,每个节点上可以存储一个或多个哈希槽,也就是说当前 Redis Cluster 支持的最大节点数就是 4096。Redis Cluster 使用的分布式算法也很简单:crc16(key) % HASH_SLOTS_NUMBER。
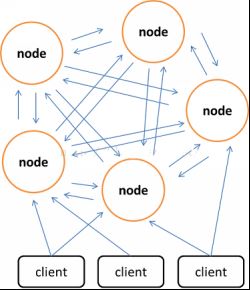
图 7 Redis 分布式架构
为了保证单点故障下的数据可用性,Redis Cluster 引入了 Master 节点和 Slave 节点。如图 4 所示,在 Redis Cluster 中,每个 Master 节点都会有对应的两个用于冗余的 Slave 节点。这样在整个集群中,任意两个节点的宕机都不会导致数据的不可用。当 Master 节点退出后,集群会自动选择一个 Slave 节点成为新的 Master 节点。

图 8 Redis Cluster 中的 Master 节点和 Slave 节点
Redis 和 Memcached 整体对比
Redis 的作者 Salvatore Sanfilippo 曾经对这两种基于内存的数据存储系统进行过比较,总体来看还是比较客观的,现总结如下:
1)性能对比:由于 Redis 只使用单核,而 Memcached 可以使用多核,所以平均每一个核上 Redis 在存储小数据时比 Memcached 性能更高。而在 100k 以上的数据中,Memcached 性能要高于 Redis,虽然 Redis 最近也在存储大数据的性能上进行优化,但是比起 Memcached,还是稍有逊色。
2)内存使用效率对比:使用简单的 key-value 存储的话,Memcached 的内存利用率更高,而如果 Redis 采用 hash 结构来做 key-value 存储,由于其组合式的压缩,其内存利用率会高于 Memcached。
3)Redis 支持服务器端的数据操作:Redis 相比 Memcached 来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在 Memcached 里,你需要将数据拿到客户端来进行类似的修改再 set 回去。这大大增加了网络 IO 的次数和数据体积。在 Redis 中,这些复杂的操作通常和一般的 GET/SET 一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么 Redis 会是不错的选择。
关于 redis 与 memcached 的区别是什么就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
向 AI 问一下细节










