共计 11234 个字符,预计需要花费 29 分钟才能阅读完成。
自动写代码机器人,免费开通
这篇文章主要介绍 Redis 的简介分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
1 Redis 简介
什么是 Redis
Redis 是完全开源免费的,遵守 BSD 协议,是⼀个⾼性能(NOSQL)的 key-value 数据库。Redis 是⼀个开源的使⽤ ANSI C 语⾔编写、⽀持⽹络、可基于内存亦可持久化的⽇志型、Key-Value 数据库,并提供多种语⾔的 API。
BSD 是“Berkeley Software Distribution”的缩写,意思是“伯克利软件发⾏版”。BSD 开源协议是⼀个给与使⽤者很⼤⾃由的协议。可以⾃由的使⽤,修改源代码,也可以将修改后的代码作
为开源或者专有软件再发布。BSD 由于允许使⽤者修改或者重新发布代码,也允许使⽤或在 BSD 代码上开发商业软件发布和销售,因此是
对商业集成很友好的协议。Linux:Ubuntu Redhat CentosNosql:
Nosql, 泛指⾮关系型数据库,Nosql 即 Not-only SQL, 他作为关系型数据库的良好补充。随着互联⽹的
兴起,⾮关系型数据库现在成为了⼀个极其热⻔的新领域,⾮关系型数据库产品的发展⾮常迅速2 Redis 安装
2.1 安装前准备
Redis 官⽹
官⽅⽹站:http://redis.io
中⽂官⽹:http://redis.cn
官⽅⽹站下载:http://redis.io/download
Redis 安装
Linux
Redis 是 C 语⾔开发,安装 Redis 需要先将官⽹下载的源码进⾏编译,编译依赖 GCC 环境,如果没有 GCC 环境,需要安装 GCC
$ wget http://download.redis.io/releases/redis-5.0.5.tar.gz
$ tar xzf redis-5.0.5.tar.gz
$ cd redis-5.0.5$ makeWindows
直接解压即可
建议 redis 安装的⽬录增加到环境变量
2.2 Redis 的启动
Linux 启动 Redis 服务端
进⼊对应的安装⽬录
cd /usr/local/redis执⾏命令
./bin/redis-server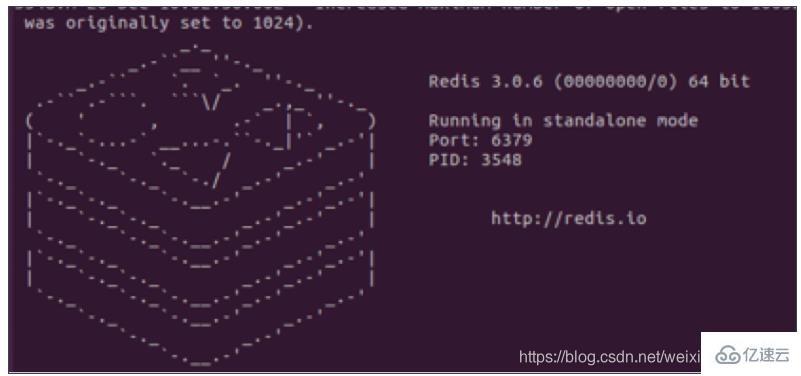
Linux 启动 Redis 客户端
./bin/redis-cliWindows 启动 Redis 服务端
进⼊对应的安装⽬录,打开命令窗⼝
执⾏命令
redis-server redis.window.conf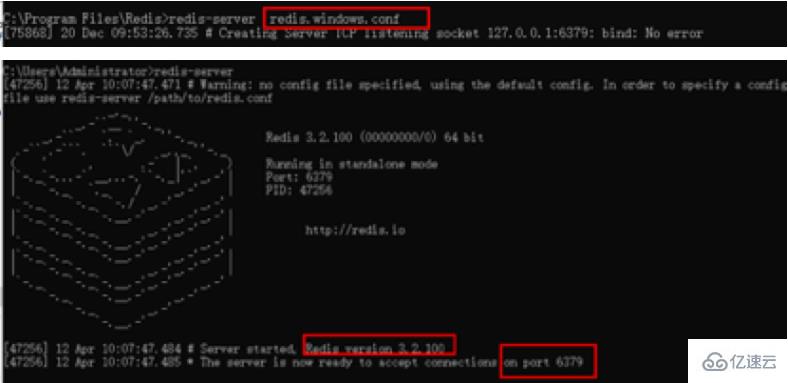
Windows 启动 Redis 客户端
进⼊对应的安装⽬录,打开命令窗⼝
执⾏命令
redis-cli客户端启动成功之后的图:
3 Redis 核⼼配置⽂件 Redis.conf
*1. Redis 默认不是以守护进程的⽅式运⾏,可以通过该配置项修改,使⽤ yes 启动守护进程
daemonize no2. 当客户端闲置多⻓时间后关闭连接(单位是秒)
timeout 300*3. 指定 Redis 监听端⼝,默认端⼝为 6379,作者在⼀⽚博⽂中解释了为什么选⽤ 6379 作为默认端⼝,因
为 6379 在⼿机按键上 MERZ 对应的号码,⽽ MERZ 取⾃意⼤利歌⼿ Alessia Merz 的名字
port 6379*4. 绑定的主机地址
bind 127.0.0.1
5. 指定⽇志记录级别,Redis 共⽀持四个级别:debug、verbose、notice、warning
loglevel verbose6. 数据库数量(单机环境下),默认数据库为 0,可以使⽤ select dbid 命令在连接上指定数据库 id
databases 16// ⾮常重要 *7. RDB 持久化策略,指定在多⻓时间内,有多少次更新操作,就将数据同步到数据⽂件,可以多个条件
save seconds changes
Redis 默认配置⽂件提供了三个条件
save 900 1
save 300 10
save 60 100008. 持久化⽂件名
dbfilename dump.rdb*9. 指定存储⾄本地数据库时是否压缩数据,默认为 yes,Redis 采⽤ LZF(压缩算法)压缩,如果为了节
省 CPU 时间,可以关闭该选项,但会导致数据库⽂件变得巨⼤
rdbcompression yes*10. 设置 Redis 连接密码,如果配置了连接密码,客户端在连接 Redis 的时候需要通过 AUTH password 命令提供密码,默认关闭
requirepass foobared// AOF 配置 *11. 指定是否在每次操作后进⾏⽇志记录,Redis 在默认情况下是关闭的
appendonly no*12. AOF ⽂件的名字
appendfilename appendonly.aof *13. aof 策略, 分为三种,always 表示每次操作都会记录⽇志,everysec 表示每秒记录⼀次⽇志,no 表
示不记录⽇志
# appendfsync always
appendfsync everysec
# appendfsync no
Redis 持久化总结:
RDB:是 Redis 默认的持久化机制。RDB 相当于照快照,保存的是⼀种状态。⼏⼗ GB 的数据 —— ⼏ KB
的快照
快照是默认的持久化⽅式,这种⽅式是就是将内存中数据以快照的⽅式写⼊到⼆进制⽂件中,默认的⽂件名为 dump.rdb。
优点:快照保存数据极快、还原数据极快
适⽤于容灾备份
缺点:⼩内存机器不适合使⽤,RDB 机制符合要求就会照快照,可能会丢失数据
快照条件:
1、服务器正常关闭时 ./bin/ shutdownredis-cli
2、key 满⾜⼀定条件,会进⾏快照
AOF:由于快照⽅式是在⼀定时间间隔内做⼀次的,那么如果 redis 意外 down 掉的话,就会丢失最后⼀次快照后的所有修改。如果应⽤要求不能丢失任何修改的话,可以采取 aof 持久化⽅式。
Append-only file:aof ⽐快照⽅式有更好的持久化性,是由于在使⽤ aof 持久化⽅式时,redis 会将每⼀个收到的写命令都通过 write 函数追加到⽂件中(默认 appendonly.aof)。当 redis 重启时会通过执⾏⽂件中保存的写命令来在内存中重建整个数据库的内容。
有三种⽅式如下:(默认是每秒⼀次)
appendonly yes 启⽤ aof 持久化⽅式
appendsync always 收到写命令就⽴即写⼊磁盘,最慢,但是保证完全的持久化
appendsync 每秒钟写⼊磁盘⼀次,在性能和持久化⽅⾯做了很好的折中
appendsync no 完全依赖 os,性能最好,持久化没有保证
4 Redis 常⽤数据类型以及应⽤场景
Redis ⽀持五种数据类型:String(字符串),hash(哈希),list(列表),set(集合)以及 zset(sorted set:有序集合)等
4.1 String
string 是 Redis 最基本的类型,⼀个 key 对应⼀个 value,⼀个键最⼤能存储 512MB。
string 类型是⼆进制安全的。意思是 Redis 的 string 可以包含任何数据。⽐如 jpg 图⽚或者序列化对象。
⼆进制安全是指,在传输数据时,保证⼆进制数据的信息安全,也就是不被篡改、破译等,如果有被攻
击,能够及时检测出来
跟之前的 map ⾮常类似。Value 是字符串。
SET key value
GET key
INCR 可以对应的 key 的数值(整型的数值)加⼀( 原⼦操作)INCRBY 给数值加上⼀个步⻓
SETEX expire 过期
SETNX not exist key 不存在的时候再去赋值应⽤场景:很常⻅的场景⽤于统计⽹站访问数量 pv(Page view),当前在线⼈数等。incr 命令(++ 操 作)
4.2 List
Redis 的列表允许⽤户从序列的两端推⼊或者弹出元素,列表由多个字符串值组成的有序可重复的序列,是链表结构,所以向列表两端添加元素的时间复杂度为 o(1),获取越接近两端的元素速度就越快。这意味着即使是⼀个有⼏千万个元素的列表,获取头部或尾部的 10 条记录也是极快的。List 中可以包含的最⼤元素数量是 4294967295。
操作命令:LPUSH 后⾯的元素放在栈顶
LPOP 返回第⼀个元素,并且在列表上删除该元素 (栈顶)LLEN 返回当前的 list 列表的⻓度
LINDEX 返回当前的 list 的指定 index 下标的元素。没有返回 nil,0 表示栈顶的元素
LINSERT 插⼊的位置是按照 index 的顺序,Before 的话得注意 index 的值
LPUSHX 如果 list 存在,再去 push
LRANGE 可以⽅便的查看某个 index 范围内的 list 的值。输⼊的 index 是从 0 开始,显示的标号是从 1 开始的。LREM 删除 list ⾥的指定的前⼏个(指定 value 的)元素
删除指定位置的元素:没有
LSET 设置指定的位置的元素的值 (修改) 输⼊的 index 是从 0 开始,显示的标号是从 1 开始的。应⽤场景:1. 最新消息排⾏榜。2. 消息队列,以完成多程序之间的消息交换。可以⽤ push 操作将任务存
在 list 中(⽣产者),然后线程在⽤ pop 操作将任务取出进⾏执⾏。(消费者)
4.3 Hash(⼆维表)
Redis 中的散列可以看成具有 String key 和 String value 的 map 容器,可以将多个 key-value 存储到⼀个 key 中。每⼀个 Hash 可以存储 4294967295 个键值对。
HSET
HSET key field value
将哈希表 key 中的域 field 的值设为 value 。如果 key 不存在,⼀个新的哈希表被创建并进⾏ HSET 操作。如果域 field 已经存在于哈希表中,旧值将被覆盖。HGET 返回哈希表 key 中给定域 field 的值。如果不存在,返回 nil
HEXISTS
HEXISTS key field
查看哈希表 key 中,给定域 field 是否存在。HGETALL
HGETALL key
返回哈希表 key 中,所有的域和值。在返回值⾥,紧跟每个域名 (field name) 之后是域的值(value),所以返回值的⻓度是哈希表⼤⼩的
HKEYS
HKEYS key
返回哈希表 key 中的所有值。返回哈希表 key 中值的数量。HVALS
HVALS key
返回哈希表 key 中所有域的值。HINCRBY
HINCRBY key field increment
为哈希表 key 中的域 field 的值加上增量 increment 。增量也可以为负数,相当于对给定域进⾏减法操作。如果 key 不存在,⼀个新的哈希表被创建并执⾏ HINCRBY 命令。如果域 field 不存在,那么在执⾏命令前,域的值被初始化为 0 。对⼀个储存字符串值的域 field 执⾏ HINCRBY 命令将造成⼀个错误。本操作的值被限制在 64 位 (bit) 有符号数字表示之内。HMGET
HMGET key field [field ...]返回哈希表 key 中,⼀个或多个给定域的值。如果给定的域不存在于哈希表,那么返回⼀个 nil 值。因为不存在的 key 被当作⼀个空哈希表来处理,所以对⼀个不存在的 key 进⾏ HMGET 操作将
返回⼀个只带有 nil 值的表。HMSET
HMSET key field value [field value ...]同时将多个 field-value (域 - 值)对设置到哈希表 key 中。此命令会覆盖哈希表中已存在的域。如果 key 不存在,⼀个空哈希表被创建并执⾏ HMSET 操作。HSETNX
HSETNX key field value
将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在。若域 field 已经存在,该操作⽆效。如果 key 不存在,⼀个新哈希表被创建并执⾏ HSETNX 命令。应⽤场景:例如存储、读取、修改⽤户属性(name,age,pwd 等)
4.4 Set(⽆序集合)
SADD
SADD key member [member ...]将⼀个或多个 member 元素加⼊到集合 key 当中,已经存在于集合的 member 元素将被忽略。假如 key 不存在,则创建⼀个只包含 member 元素作成员的集合。当 key 不是集合类型时,返回⼀个错误。SMEMBERS
SMEMBERS key
返回集合 key 中的所有成员。不存在的 key 被视为空集合。SISMEMBER
SISMEMBER key member
判断 member 元素是否集合 key 的成员。SCARD
SCARD key
返回集合 key 的基数(集合中元素的数量)。SPOP (弹出并从集合删除)SPOP key
移除并返回集合中的⼀个随机元素。如果只想获取⼀个随机元素,但不想该元素从集合中被移除的话,可以使⽤ SRANDMEMBER 命
SRANDMEMBER
SRANDMEMBER key [count]如果命令执⾏时,只提供了 key 参数,那么返回集合中的⼀个随机元素。随机取出 count 个元素(不删除)SINTER
SINTER key [key ...]返回⼀个集合的全部成员,该集合是所有给定集合的交集。不存在的 key 被视为空集。SINTERSTORE
SINTERSTORE destination key [key ...]这个命令类似于 SINTER 命令,但它将结果保存到 destination 集合,⽽不是简单地返回结果
如果 destination 集合已经存在,则将其覆盖。SUNION
SUNION key [key ...]返回⼀个集合的全部成员,该集合是所有给定集合的并集。不存在的 key 被视为空集。SUNIONSTORE
SUNIONSTORE destination key [key ...]这个命令类似于 SUNION 命令,但它将结果保存到 destination 集合,⽽不是简单地返回结果
如果 destination 已经存在,则将其覆盖。SDIFF
SDIFF key [key ...]返回⼀个集合的全部成员,该集合是所有给定集合之间的差集。不存在的 key 被视为空集。SDIFFSTORE
SDIFFSTORE destination key [key ...]这个命令的作⽤和 SDIFF 类似,但它将结果保存到 destination 集合,⽽不是简单地返回结果
如果 destination 集合已经存在,则将其覆盖。 destination 可以是 key 本身。SMOVE
SMOVE source destination member
将 member 元素从 source 集合移动到 destination 集合。SMOVE 是原⼦性操作。SREM 删除
SREM key member [member ...]移除集合 key 中的⼀个或多个 member 元素,不存在的 member 元素会被忽略。当 key 不是集合类型,返回⼀个错误。应⽤场景:
1. 利⽤交集求共同好友。
2. 利⽤唯⼀性,可以统计访问⽹站的所有独⽴ IP。
3. 好友推荐的时候根据 tag 求交集,⼤于某个 threshold(临界值的)就可以推荐。
4.5 SortSet(有序集合)
ZADD
ZADD key score member [[score member] [score member] ...]将⼀个或多个 member 元素及其 score 值加⼊到有序集 key 当中。ZCARD
ZCARD key
返回有序集 key 的基数。ZSCORE
ZSCORE key member
返回有序集 key 中,成员 member 的 score 值。如果 member 元素不是有序集 key 的成员,或 key 不存在,返回 nil 。ZCOUNT (闭区间)ZCOUNT key min max
返回有序集 key 中, score 值在 min 和 max 之间 (默认包括 score 值等于 min 或 max ) 的
成员的数量。关于参数 min 和 max 的详细使⽤⽅法,请参考 ZRANGEBYSCORE 命令。ZINCRBY
ZINCRBY key increment member
为有序集 key 的成员 member 的 score 值加上增量 increment 。ZRANGE
ZRANGE key start stop [WITHSCORES]返回有序集 key 中,指定区间内的成员。其中成员的位置按 score 值递增 (从⼩到⼤) 来排序。具有相同 score 值的成员按字典序 (lexicographical order ) 来排列。ZRANGEBYSCORE
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]返回有序集 key 中,所有 score 值介于 min 和 max 之间 (包括等于 min 或 max ) 的成员。有
序集成员按 score 值递增 (从⼩到⼤) 次序排列。根据指定的分值范围去查找
ZRANK (排名从 0 开始)ZRANK key member
返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增 (从⼩到⼤) 顺序排
ZREVRANGE
ZREVRANGE key start stop [WITHSCORES]返回有序集 key 中,指定区间内的成员。其中成员的位置按 score 值递减 (从⼤到⼩) 来排列。具有相同 score 值的成员按字典序的逆序 (reverse lexicographical order) 排列。ZREVRANGEBYSCORE
ZREVRANGE key start stop [WITHSCORES]返回有序集 key 中,指定区间内的成员。ZREVRANK
ZREVRANK key member
返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递减 (从⼤到⼩) 排序。排名以 0 为底,也就是说, score 值最⼤的成员排名为 0 。使⽤ ZRANK 命令可以获得成员按 score 值递增 (从⼩到⼤) 排列的排名。ZREM key member [member ...]移除有序集 key 中的⼀个或多个成员,不存在的成员将被忽略。当 key 存在但不是有序集类型时,返回⼀个错误。ZREMRANGEBYRANK
ZREMRANGEBYRANK key start stop
移除有序集 key 中,指定排名 (rank) 区间内的所有成员。区间分别以下标参数 start 和 stop 指出,包含 start 和 stop 在内。ZREMRANGEBYSCORE
ZREMRANGEBYSCORE key min max
移除有序集 key 中,所有 score 值介于 min 和 max 之间 (包括等于 min 或 max ) 的成员。应⽤场景:可以⽤于⼀个⼤型在线游戏的积分排⾏榜,每当玩家的分数发⽣变化时,可以执⾏ zadd 更新
玩家分数(score),此后在通过 zrange 获取⼏分 top ten 的⽤户信息。
5 Redis 的整合(Jedis)Java for Redis
5.1 导包
dependency
groupId redis.clients /groupId
artifactId jedis /artifactId
version 2.9.0 /version /dependency5.2 配置
@Configurationpublic class RedisConfig {
@Bean
public Jedis jedis(){ Jedis jedis = new Jedis( localhost , 6379);
return jedis;
}}5.3 使⽤
// 直接引⼊ @Autowiredprivate Jedis jedis;// 使⽤ 和在命令⾏客户端操作是⼀样的 jedis.set();jedis.get();jedis.hset();jedis.hget();jedis.sadd();...6 Springboot2.x 中 Redis 进⾏连接(RedisTemplate)
RedisTemplate 简介,SpringBoot 对 Redis 进⾏了⼀层模板化的封装,⽅便我们对对象进⾏操作。底层
在 SpringBoot1.x 的时候使⽤的是 Jedis,在 Springboot2.x 后使⽤的是 lettuce。
6.1 导包
dependency
groupId org.springframework.boot /groupId
artifactId spring-boot-starter-data-redis /artifactId /dependency !-- 序列化 -- dependency
groupId com.fasterxml.jackson.core /groupId
artifactId jackson-core /artifactId
version 2.10.0 /version /dependency dependency
groupId com.fasterxml.jackson.core /groupId
artifactId jackson-databind /artifactId
version 2.10.0 /version /dependency6.2 配置
@Configurationpublic class RedisConfig {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){ RedisTemplate redisTemplate = new RedisTemplate();
redisTemplate.setConnectionFactory(redisConnectionFactory);
// 定制化模板
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
redisTemplate.setKeySerializer(stringRedisSerializer);
// 设置 value JackSon 序列化⽅式
Jackson2JsonRedisSerializer jsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
// 对于不是基本类型的变量显示全类名
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
// 设置值的属性可⻅
objectMapper.setVisibility(PropertyAccessor.ALL,JsonAutoDetect.Visibility.AN
jsonRedisSerializer.setObjectMapper(objectMapper);
redisTemplate.setValueSerializer(jsonRedisSerializer);
return redisTemplate;
}}6.3 使⽤
redisTemplate.opsForValue().set();
redisTemplate.opsForHash().put();
redisTemplate.opsForList().leftPush();
redisTemplate.opsForSet().add();
redisTemplate.opsForZSet().add();7 Springboot2.x 中使⽤ Redisson 进⾏连接
Redisson:Redisson 是⼀个在 Redis 的基础上实现的 Java 驻内存数据⽹格(In-Memory Data Grid)。它不仅提供了⼀系列的分布式的 Java 常⽤对象,还提供了许多分布式服务。其中包括(BitSet , Set ,
Multimap , SortedSet , Map , List , Queue , BlockingQueue , Deque , BlockingDeque ,Semaphore , Lock , AtomicLong , CountDownLatch , Publish / Subscribe , Bloom filter ,Remote service , Spring cache , Executor service , Live Object service , Scheduler service ) Redisson 提供了使⽤ Redis 的最简单和最便捷的⽅法。Redisson 的宗旨是促进使⽤者对 Redis 的关注分离(Separation of Concern),从⽽让使⽤者能够将精⼒更集中地放在处理业务逻辑上。
开源地址:https://github.com/redisson/redisson
7.1 导包
dependency
groupId org.redisson /groupId
artifactId redisson /artifactId
version 3.5.7 /version /dependency7.2 配置
@Configurationpublic class RedissonConfig {
@Bean
public RedissonClient getRedisson(){ Config config = new Config();
config.useSingleServer().setAddress( redis://localhost:6379
return Redisson.create(config);
}}7.3 使⽤
参考命令匹配列表
8 Redis 内存淘汰策略
Redis 官⽅给的警告,当内存不⾜时,Redis 会根据配置的缓存策略淘汰部分的 Keys,以保证写⼊成功。当⽆淘汰策略时或者没有找到适合淘汰的 Key 时,Redis 直接返回 out of memory 错误。
最⼤缓存配置
在 Redis 中,允许⽤户设置的最⼤使⽤内存⼤⼩
maxmemory 512G
Redis 提供 8 种(5.0 以后)数据淘汰策略:
volatile-lru:从已设置过期时间的数据集中挑选最近最少使⽤的数据淘汰
volatile-lfu:从已设置过期的 Keys 中,删除⼀段时间内使⽤次数最少使⽤ 的 key
volatile-ttl:从已设置过期时间的数据集中挑选最近将要过期的数据进⾏淘汰
volatile-random:从已设置过期时间的数据集中随机选择数据淘汰
allkeys-lru:从数据集中挑选最近最少使⽤的数据淘汰
allkeys-lfu:从所有的 keys 中,删除⼀段时间内使⽤次数最少的 key
allkeys-random:从数据集中随机选择数据淘汰
no-enviction(驱逐):禁⽌驱逐数据(不采⽤任何淘汰策略。默认即此配置),内存不⾜时,针对写操作,返回错误信息
建议:了解了 Redis 的淘汰策略之后,在平时使⽤时应尽量主动设置 / 更新 key 的 expire 时间,主动剔除不活跃的旧数据,有助于提升查询性能
以上是“Redis 的简介分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注丸趣 TV 行业资讯频道!
向 AI 问一下细节











