共计 4133 个字符,预计需要花费 11 分钟才能阅读完成。
自动写代码机器人,免费开通
这篇文章给大家分享的是有关 MongoDB 是怎样存储数据的的内容。丸趣 TV 小编觉得挺实用的,因此分享给大家做个参考,一起跟随丸趣 TV 小编过来看看吧。
前言
想要深入了解 MongoDB 如何存储数据之前,有一个概念必须清楚,那就是 Memeory-Mapped Files。
Memeory-Mapped Files
下图展示了数据库是如何跟底层系统打交道的。
内存映射文件是 OS 通过 mmap 在内存中创建一个数据文件,这样就把文件映射到一个虚拟内存的区域。
虚拟内存对于进程来说,是一个物理内存的抽象,寻址空间大小为 2^64
操作系统通过 mmap 来把进程所需的所有数据映射到这个地址空间 (红线),然后再把当前需要处理的数据映射到物理内存 (灰线)
当进程访问某个数据时,如果数据不在虚拟内存里,触发 page fault,然后 OS 从硬盘里把数据加载进虚拟内存和物理内存
如果物理内存满了,触发 swap-out 操作,这时有些数据就需要写回磁盘,如果是纯粹的内存数据,写回 swap 分区,如果不是就写回磁盘。
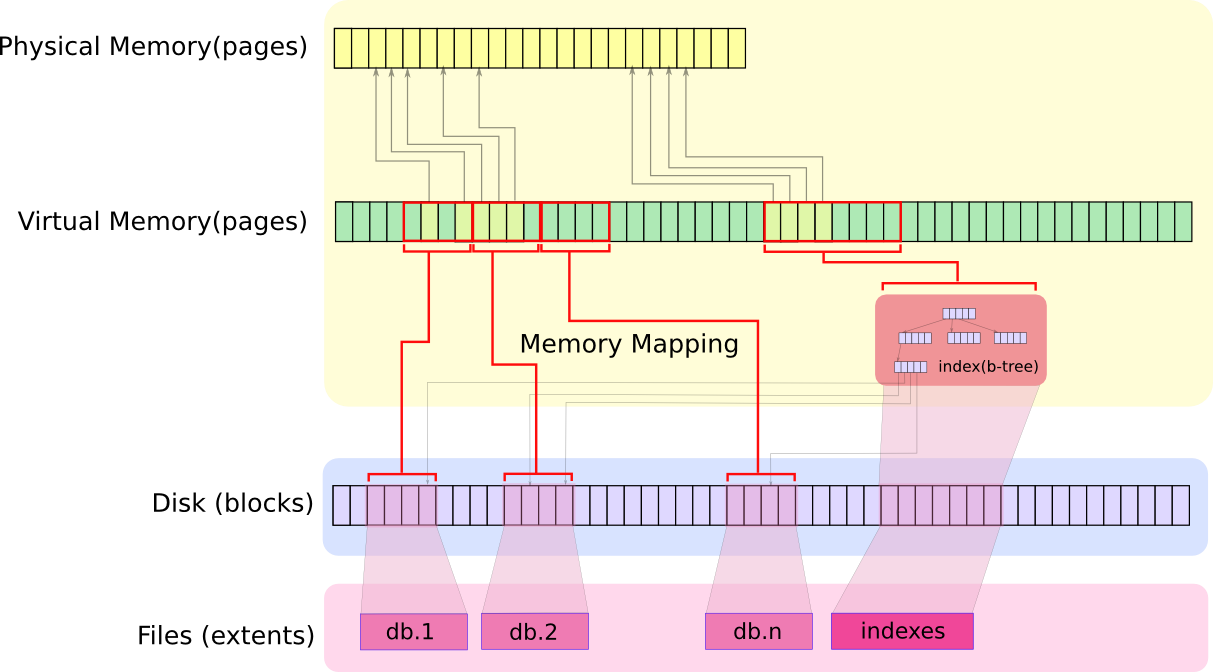
MongoDB 的存储模型
有了内存映射文件,要访问的数据就好像都在内存里面,简单化了 MongoDB 访问和修改数据的逻辑
MongoDB 读写都只是和虚拟内存打交道,剩下都交给 OS 打理
虚拟内存大小 = 所有文件大小 + 其他一些开销 (连接,堆栈)
如果 journal 开启,虚拟内存大小差不多翻番
使用 MMF 的好处 1:不用自己管理内存和磁盘调度 2:LRU 策略 3:重启过程中,Cache 依然在。
使用 MMF 的坏处 1:RAM 使用会受磁盘碎片的影响,高预读也会影响 2:无法自己优化调度算法,只能使用 LRU
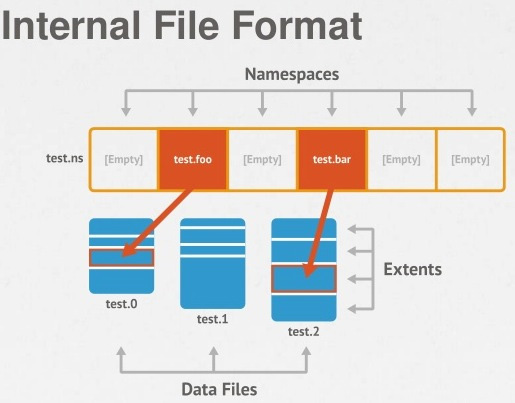
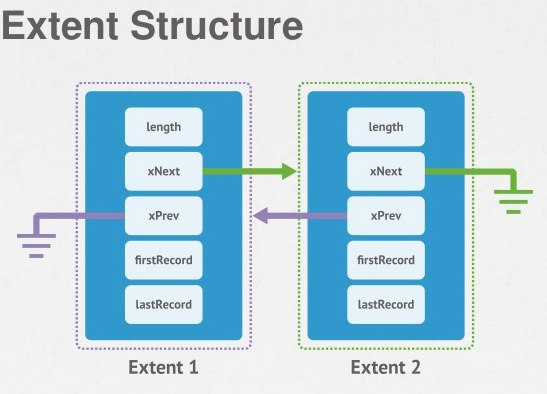

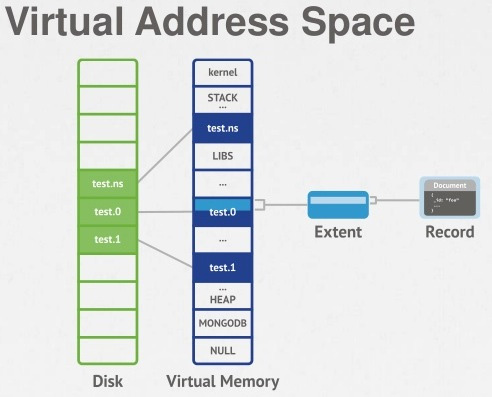
磁盘上的文件是有 extent 构成,分配集合空间的时候也是以 extent 为单位进行分配的
一个集合有一个或者多个 etent
ns 文件里面命名空间记录指向那个集合的第一个 extent
数据文件与空间分配
当创建数据库时 (其实 MongoDB 没有显式创建数据库的方法,在向数据库中的集合写入数据时会自动创建该数据库),MongoDB 会在磁盘上分配一组数据文件,所有集合,索引和数据库的其他元数据都保存在这些文件里。数据文件被放在启动时指定的 dbpath 里,默认放入 /data/db 下面。典型的一个文件组织结构如下:
$ cat /data/db
$ ls -al
-rw------- 1 root root 16777216 09-18 00:54 local.ns
-rw------- 1 root root 67108864 09-18 00:54 local.0
-rw------- 1 root root 2146435072 09-18 00:55 local.1
-rw------- 1 root root 2146435072 09-18 00:56 local.2
-rw------- 1 root root 2146435072 09-18 00:57 local.3
-rw------- 1 root root 2146435072 09-18 00:58 local.4
-rw------- 1 root root 2146435072 09-18 00:59 local.5
-rw------- 1 root root 2146435072 09-18 01:01 local.6
-rw------- 1 root root 2146435072 09-18 01:02 local.7
-rw------- 1 root root 2146435072 09-18 01:03 local.8
-rw------- 1 root root 2146435072 09-18 01:04 local.9
-rw------- 1 root root 2146435072 09-18 01:05 local.10
-rw------- 1 root root 16777216 09-18 01:06 test.ns
-rw------- 1 root root 67108864 09-18 01:06 test.0
-rw------- 1 root root 134217728 09-18 01:06 test.1
-rw------- 1 root root 268435456 09-18 01:06 test.2
-rw------- 1 root root 536870912 09-18 01:06 test.3
-rw------- 1 root root 1073741824 09-18 01:07 test.4
-rw------- 1 root root 2146435072 09-18 01:07 test.5
-rw------- 1 root root 2146435072 09-18 01:09 test.6
-rw------- 1 root root 2146435072 09-18 01:11 test.7
-rw------- 1 root root 2146435072 09-18 01:13 test.8
-rwxr-xr-x 1 root root 6 09-18 13:54 mongod.lock
drwxr-xr-x 2 root root 4096 11-13 18:39 journal
drwxr-xr-x 2 root root 4096 11-13 19:02 _tmp
mongod.lock 中存储了服务器的进程 ID,是一个进程锁定文件。数据文件是依据所属的数据库命名的。
test.ns 是第一个生成的文件 (ns 扩展名就是 namespace 的意思),数据库中的每个集合和索引都有自己的命名空间,每个命名空间的元数据都存放在这个文件里。默认情况下,.ns 文件大小固定在 16MB,大约可以存储 24000 个命名空间。也就是说数据库中的索引和集合总数不能超过 24000,该值可以通过 mongod 的–nssize 选项进行定制。
像 test.0 这样以 0 开始的整数结尾的文件就是集合和索引数据文件。刚开始的时候,即使只有一条数据,MongoDB 也会预分配几个文件,这种预分配的做法,能让数据尽可能连续存储,减少磁盘碎片。在像数据库添加数据时,MongoDB 会分配更多的数据文件。每个新数据文件的大小都是上一个已分配文件的两倍 (64M- 128M- 256M),直到预分配文件大小的上限 2G。此处基于一个假设,如果总数据大小呈恒定速率增长,应该逐渐增加数据文件分配的空间。当然这个预分配策略也是可以通过–noprealloc 关掉,但是不建议在 production 环境下使用。
默认的 local 数据库,该数据库不参与 replication。当 mongod 是一个副本集的成员时,在 local 数据库中就有一个叫做 oplog.rs 的预分配的 capped 集合,预分配的大小为磁盘空间的 5%。这个大小可以通过–oplogSize 进行调整。oplog 主要用于副本集 Primary 和 Secondary 成员见的 replication,它的大小限制了两个副本集之间,在重新完全同步之前,允许多长时间不同步。
journal 目录,journal 功能 2.4 版本默认是开启的。
可以使用 db.stats() 来确认已使用空间和已分配空间。
{
db : test ,
collections : 37,
objects : 317894523, # 文档总个数
avgObjSize : 232.3416429039893, # 单位是字节
dataSize : 73860135744, # 集合中所有数据实际大小 (包括 padding factor 为每个文档分配的额外空间以允许文档增长)。该值在文档 size 变小的时候,这个值不会减少,除非文档被删除,或者执行 compact 或者 repairDatabase 操作
storageSize : 97834319392, # 分配给集合的空间大小 (包括为集合增长预留的额外空间和未分配的已删除空间,即不会因为文档 size 变小或者删除而减小),实际上从数据文件中分配给集合的空间是以块为单位,也称之为 extents,即分配的 extents 的大小
numExtents : 385,
indexes : 86,
indexSize : 58687466992,
fileSize : 182380920832, # 所有数据文件大小之和,不包括命名空间文件 (ns 文件)
nsSizeMB : 16,
dataFileVersion : {
major : 4,
minor : 5
},
ok : 1
}使用 db.accesslog.stats() 确认某个集合的使用量
{
ns : test.accesslog ,
count : 145352932,
size : 37060264352, #实际数据大小,不包括索引
avgObjSize : 254.967435758365,
storageSize : 45794676448, # 预分配的数据存储空间
numExtents : 42,
nindexes : 4,
lastExtentSize : 2146426864,
paddingFactor : 1, # 当文档因更新 size 增长时事先 padding 可以提速,减少碎片的产生
systemFlags : 1,
userFlags : 0,
totalIndexSize : 31897944512,
indexSizes : {
_id_ : 6722168208,
action_1_time_1 : 8606482752,
gz_id_1_action_1_time_1 : 10753778336,
time_1 : 5815515216
},
ok : 1
}感谢各位的阅读!关于“MongoDB 是怎样存储数据的”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
向 AI 问一下细节











