共计 2498 个字符,预计需要花费 7 分钟才能阅读完成。
自动写代码机器人,免费开通
怎么在 mysql 中对于索引使用率进行监控?很多新手对此不是很清楚,为了帮助大家解决这个难题,下面丸趣 TV 小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
1、查看当前索引使用情况
我们可以通过下面语句查询当前索引使用情况:
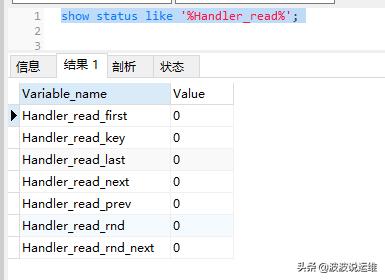
Handler_read_first 代表读取索引头的次数,如果这个值很高,说明全索引扫描很多。
Handler_read_key 代表一个索引被使用的次数,如果我们新增加一个索引,可以查看 Handler_read_key 是否有增加,如果有增加,说明 sql 用到索引。
Handler_read_next 代表读取索引的下列,一般发生 range scan。
Handler_read_prev 代表读取索引的上列,一般发生在 ORDER BY … DESC。
Handler_read_rnd 代表在固定位置读取行,如果这个值很高,说明对大量结果集进行了排序、进行了全表扫描、关联查询没有用到合适的 KEY。
Handler_read_rnd_next 代表进行了很多表扫描,查询性能低下。
其实比较多应用场景是当索引正在工作,Handler_read_key 的值将很高,这个值代表了一个行将索引值读的次数,很低的值表明增加索引得到的性能改善不高,因为索引并不经常使用。
Handler_read_rnd_next 的值高则意味着查询运行低效,并且应该建立索引补救。这个值的含义是在数据文件中读下一行的请求数。如果正进行大量的表 扫描,Handler_read_rnd_next 的值较高,则通常说明表索引不正确或写入的查询没有利用索引
2、查看索引是否被使用到
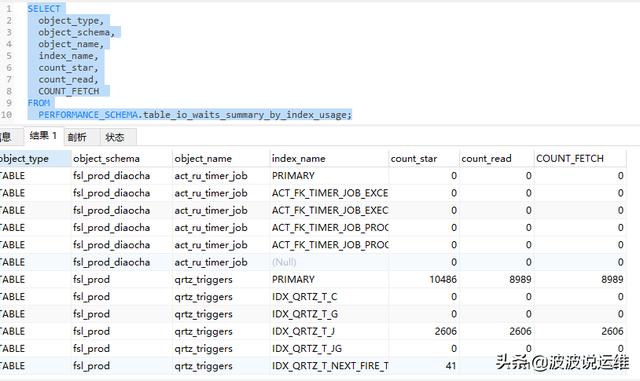
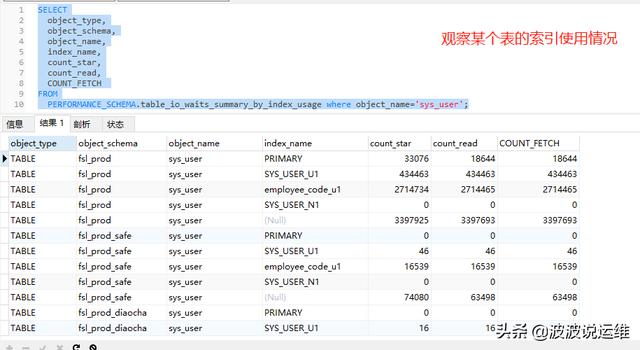
SELECT
object_type,
object_schema,
object_name,
index_name,
count_star,
count_read,
COUNT_FETCH
PERFORMANCE_SCHEMA.table_io_waits_summary_by_index_usage;
如果 read,fetch 的次数都为 0 的话,就是没有被使用过的。
3、查看使用了哪些索引
explain 相关 sql,查看 type 表示查询用到了那种索引类型
+-----+-------+-------+-----+--------+-------+---------+-------+
| ALL | index | range | ref | eq_ref | const | system | NULL |
+-----+-------+-------+-----+--------+-------+---------+-------+
从最好到最差依次是:
system const eq_ref ref fulltext ref_or_null index_merge unique_subquery index_subquery range index ALLsystem 表中只有一条记录,一般来说只在系统表里出现。
const 表示通过一次索引查询就查询到了,一般对应索引列为 primarykey 或者 unique where 语句中 指定 一个常量,因为只匹配一行数据,MYSQL 能把这个查询优化为一个常量,所以非常快。
eq_ref 唯一性索引扫描。此类型通常出现在多表的 join 查询,对于每一个从前面的表连接的对应列,当前表的对应列具有唯一性索引,最多只有一行数据与之匹配。
ref 非唯一性索引扫描。同上,但当前表的对应列不具有唯一性索引,可能有多行数据匹配。此类型通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了 最左前缀 规则索引的查询.
range 索引的范围查询。查询索引关键字某个范围的值。
index 全文索引扫描。与 all 基本相同,扫描了全文,但查询的字段被索引包含,故不需要读取表中数据,只需要读取索引树中的字段。
all 全文扫描。未使用索引,效率最低。
顺便提几个优化注意点:
1、优化 insert 语句:
1)尽量采用 insert into test values(),(),(),()…
2)如果从不同客户插入多行,能通过使用 insert delayed 语句得到更高的速度,delayed 含义是让 insert 语句马上执行,其实数据都被放在内存队列中个,并没有真正写入磁盘,这比每条语句分别插入快的多;low_priority 刚好相反,在所有其他用户对表的读写完后才进行插入。
3)将索引文件和数据文件分在不同磁盘上存放(利用建表语句)
4)如果进行批量插入,可以增加 bulk_insert_buffer_size 变量值方法来提高速度,但是只对 MyISAM 表使用
5)当从一个文本文件装载一个表时,使用 load data file,通常比使用 insert 快 20 倍
2、优化 group by 语句:
默认情况下,mysql 会对所有 group by 字段进行排序,这与 order by 类似。如果查询包括 group by 但用户想要避免排序结果的消耗,则可以指定 order by null 禁止排序。
3、优化 order by 语句:
某些情况下,mysql 可以使用一个索引满足 order by 字句,因而不需要额外的排序。where 条件和 order by 使用相同的索引,并且 order by 的顺序和索引的顺序相同,并且 order by 的字段都是升序或者降序。
4、优化嵌套查询:
mysql4.1 开始支持子查询,但是某些情况下,子查询可以被更有效率的 join 替代,尤其是 join 的被动表待带有索引的时候,原因是 mysql 不需要再内存中创建临时表来完成这个逻辑上需要两个步骤的查询工作。
最后提一个点:
一个表最多 16 个索引, 最大索引长度 256 字节,索引一般不明显影响插入性能(大量小数据例外),因为建立索引的时间开销是 O(1) 或者 O(logN)。不过太多索引也是不好的,毕竟更新之类的操作都需要去维护索引。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注丸趣 TV 行业资讯频道,感谢您对丸趣 TV 的支持。
向 AI 问一下细节











