共计 3256 个字符,预计需要花费 9 分钟才能阅读完成。
自动写代码机器人,免费开通
使用 oracle 怎么实现一对多数据分页查询筛选?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
先来看下第一次 sql 是如何写的
查询之后在外面做分页,很正常的逻辑,但是大家都发现了,这是一个多表查询,而且是一对多关系,这就有点问题了
先来看一个图
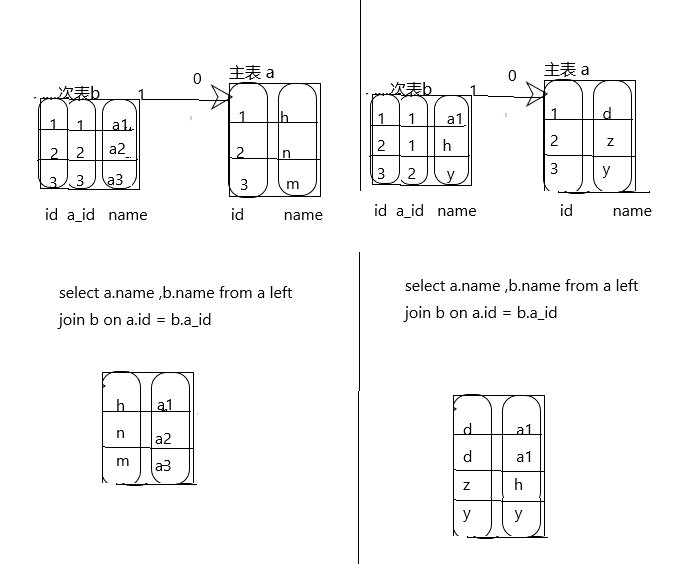
问题出现在哪呢?
1、需要对主表做分页数据查询,如:
limit 1,10 或 SELECT * FROM (SELECT A.* ,ROWNUM R FROM (select _ from car) A WHERE ROWNUM = ${limitEnd} ) B WHERE R = ${limitStart} ]
以上是对上表做数据统计,然后分页,
2、根据传入字段做筛选,如:车辆的座位数,排量,
出现的问题
因为业务数据庞大,一对多关系数据冗余,出现数据偏移
主要解决思路如下
嗯,下来个图示吧

1、对子表合并,做行转列,2、在主表做分页筛选时就不会出现,因为一对多关系数据冗余,出现数据偏移
SELECT * FROM (SELECT A.* ,ROWNUM R FROM (
select
T_CAR. ID as car_ID , T_CAR. CAR_NAME as car_CAR_NAME , T_CAR. VIN_NUMBER
as car_VIN_NUMBER ,car_label.label_ids
FROM T_CAR
left join (select CAR_ID,wm_concat(LABLE_ID) as label_ids from T_Car_label group by CAR_ID) car_label on car_label.CAR_ID = T_CAR.ID
where FIND_IN_SET(4aa06d2b9e904fe8bfeba3505c5dad6a ,label_ids)=1
) A WHERE ROWNUM =10 ) B WHERE R =
FIND_IN_SET:由于写在 sql 里的筛选很繁琐,此方法是一个储存函数 这个实现不是很好
此函数在 mysql 下有定义,但是此处因为与业务相关,内部做了一些更改
具体修改是当传进了一个 {1,2,3,4} 格式的数据时也可以做出条件筛选
create or replace FUNCTION FIND_IN_SET(piv_str1 varchar2, piv_str2 varchar2, p_sep varchar2 := ,)
RETURN NUMBER IS
l_idx_a number:=0; -- 用于计算 piv_str1 中分隔符的位置
l_idx_b number:=0; -- 用于计算 piv_str2 中分隔符的位置
str_a varchar2(4000); -- 根据分隔符截取的子字符串
str_b varchar2(4000); -- 根据分隔符截取的子字符串
piv_str_a varchar2(4000) := piv_str1; -- 将 piv_str1 赋值给 piv_str_a
piv_str_b varchar2(4000) := piv_str2; -- 将 piv_str2 赋值给 piv_str_b
res number:=0; -- 返回结果
BEGIN
-- 如果 piv_str_a 中没有分割符,直接循环判断 piv_str_a 和 piv_str_b 是否相等,相等 res=1
IF instr(piv_str_a, p_sep, 1) = 0 THEN
-- 如果 piv_str2 中没有分割符,直接判断 piv_str1 和 piv_str2 是否相等,相等 res=1
IF instr(piv_str_b, p_sep, 1) = 0 THEN
IF piv_str_a = piv_str_b THEN
res:= 1;
END IF;
ELSE
-- 循环按分隔符截取 piv_str_b
LOOP
l_idx_b := instr(piv_str_b,p_sep);
-- 当 piv_str 中还有分隔符时
IF l_idx_b 0 THEN
-- 截取第一个分隔符前的字段 str
str_a:= substr(piv_str_b,1,l_idx_b-1);
-- 判断 str 和 piv_str_a 是否相等,相等 res=1 并结束循环判断
IF str_a = piv_str_a THEN
res:= 1;
EXIT;
END IF;
piv_str_b := substr(piv_str_b,l_idx_b+length(p_sep));
ELSE
-- 当截取后的 piv_str 中不存在分割符时,判断 piv_str 和 piv_str1 是否相等,相等 res=1
IF piv_str_a = piv_str_b THEN
res:= 1;
END IF;
-- 无论最后是否相等,都跳出循环
EXIT;
END IF;
END LOOP;
-- 结束循环
END IF;
-- 循环按分隔符截取 piv_str_a
l_idx_a := instr(piv_str_a,p_sep);
-- 当 piv_str_a 中还有分隔符时
IF l_idx_a 0 THEN
-- 截取第一个分隔符前的字段 str
str_a:= substr(piv_str_a,1,l_idx_a-1);
-- 如果 piv_str_b 中没有分割符,直接判断 piv_str1 和 piv_str 是否相等,相等 res=1
IF instr(piv_str_b, p_sep, 1) = 0 THEN
-- 判断 str_a 和 piv_str_b 是否相等,相等 res=1 并结束循环判断
IF str_a = piv_str_b THEN
res:= 1;
EXIT;
END IF;
ELSE
-- 循环按分隔符截取 piv_str_b
LOOP
l_idx_b := instr(piv_str_b,p_sep);
-- 当 piv_str 中还有分隔符时
IF l_idx_b 0 THEN
-- 截取第一个分隔符前的字段 str
str_b:= substr(piv_str_b,1,l_idx_b-1);
-- 判断 str 和 piv_str1 是否相等,相等 res=1 并结束循环判断
IF str_b = str_a THEN
res:= 1;
EXIT;
END IF;
piv_str_b := substr(piv_str_b,l_idx_b+length(p_sep));
ELSE
-- 当截取后的 piv_str 中不存在分割符时,判断 piv_str 和 piv_str1 是否相等,相等 res=1
IF piv_str_a = piv_str_b THEN
res:= 1;
END IF;
-- 无论最后是否相等,都跳出循环
EXIT;
END IF;
END LOOP;
-- 结束循环
END IF;
piv_str_a := substr(piv_str_a,l_idx_a+length(p_sep));
ELSE
-- 当截取后的 piv_str 中不存在分割符时,判断 piv_str 和 piv_str1 是否相等,相等 res=1
IF piv_str_a = piv_str_b THEN
res:= 1;
END IF;
-- 无论最后是否相等,都跳出循环
EXIT;
END IF;
END LOOP;
-- 结束循环
END IF;
-- 返回 res
RETURN res;
END FIND_IN_SET;关于使用 oracle 怎么实现一对多数据分页查询筛选问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注丸趣 TV 行业资讯频道了解更多相关知识。
向 AI 问一下细节











