共计 1073 个字符,预计需要花费 3 分钟才能阅读完成。
自动写代码机器人,免费开通
这篇文章给大家介绍 MySQL 中怎么维护主从信息的元数据,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
1.*** 个维度是单点实例,单点实例是那些测试环境,数据流转节点或者业务优先级不高的业务。这些业务允许数据丢失,甚至允许环境重建,有一个基本的备份即可,这类的业务我们首先剥离出来,后面处理的时候就可以可以绕过这些节点,比如对于这些节点来说,可能不需要备份,可能不需要每天备份,压根不需要增量备份,binlog 备份,按照这个规划,做了这些信息确认之后,后期要完成的备份恢复就有据可依,要不费了半天劲,*** 发现业务优先级不高,做事情的性价比就大打折扣。
2. 第二个维度是数据库角色,数据库的角色其实不能严格意义上归类为 Master,Slave,其实可以有更多的类型,比如单点业务,我们可以归类为 SingleDB, 如果是中继节点(show master status 或者 show slave status 持有双重角色),我们可以归类为 RelayDB, 如果是主库或者是从库即为 Master,Slave, 如果属于 MHA 或者 MGR 的集群环境等,其实这个角色可以更加清晰,对于这部分信息我们需要做减法,即 MHA 或者 MGR 的环境,这类信息可以归类为集群信息,我们可以对其他的信息按照 SingleDB,RelayDB,Master,Slave 这四个维度来统计即可。
要实现这个功能,就有一些技巧需要补充了。
我们在这里需要两个脚本:
1)通过 IP 和端口信息得知实例的角色(Master,Slave,RelayDB,SingleDB 等)
2)通过 Slave 和 RelayDB 的信息来得到 Master 的信息,亮点也就在此,通过这些信息我们可以清晰的达到一个复制关系图,甚至可以看到一些意想不到的问题。
比如下面的 IP 信息,数据库角色是中继节点 RelayDB(既是 Master 又是 Slave)
我们根据 IP 的后两段内容搜索得到下面的一个基本列表。
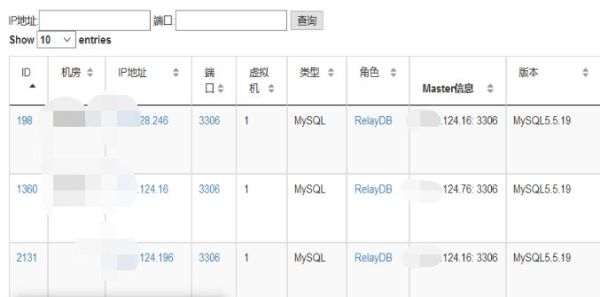
这样一个关系,如果自己来刻意维护,其实很容易就会迷茫,或者意识不到这种级联关系的存在,但是我们对这些数据进行抽象,就很快能够得到这样的饿一个关系图,原来是这样的一个级联关系。这样一来 124.16 这个中继节点的角色和上下游的关系就很清晰了,那么从这个角度来看,我们是否需要对 124.76 做数据的备份就很容易得出结论了。

关于 MySQL 中怎么维护主从信息的元数据就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
向 AI 问一下细节










