共计 1079 个字符,预计需要花费 3 分钟才能阅读完成。
自动写代码机器人,免费开通
这篇文章给大家介绍 MongoDB 中怎么搭建延时节点从库,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
MongoDB 搭建延时节点从库
【概念说明】
延时节点也是从主节点复制数据,然而延时节点中的数据集将会比复制集中主节点的数据延后。举个例子,现在是 09:52,如果延时节点延后了 1 小时,那么延时节点的数据集中将不会有 08:52 之后的操作。
mongo 并不像有些关系型数据库那样有类似 oracle 的 archive、mysql 的 binlog 这样的归档文件,他的文件是 oplog,是覆盖循环写的,如果想要找之前的数据,恢复起来较为麻烦,故考虑这点采用延时节点从库。由于延时节点的数据集是延时的,因此它可以帮助我们在人为误操作或是其他意外情况下恢复数据。举个例子,当应用升级失败,或是误操作删除了表和数据库时,我们可以通过延时节点进行数据恢复。
【注意事项】
1 优先级 priority 必须为 0,以防延迟节点变为主库
2 必须 hidden 成员,这是防止用户在读从库时候查到延迟节点
3 也参与主库的投票,在 rs.conf() 的里面 members[0].votes 也是为 1
4 延迟节点在延迟时间后复制应用源端的 oplog,如果延迟设置的很大,必须等于或大于期望维护窗口时间。必须小于 oplog 的存储能力
5 在分片集群中,当 平衡器打开的时候延时节点效果有限。因为在延时的时间段内进行过数据段迁移的话,复制集中的延时节点就无法为还原分片集群提供有效的帮助。
【方法】
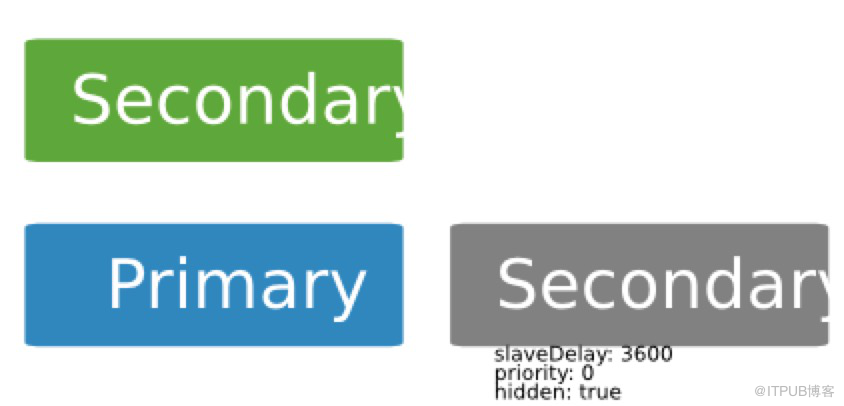
如下是拥有 3 个成员的副本集:一主两从。当一个成员设置为 3600 秒后延迟,这个延迟成员必须 hidden 且优先级为 0
【配置方式】
1 members[n].priority=0
2 members[n].hidden=true
3 members[n].slaveDelay=3600
{_id :
num ,
host :
hostname:port ,
priority : 0,
slaveDelay :
seconds ,
hidden : true
}
具体例子:
cfg=rs.conf() /* 找到需要改为延迟性同步的数组号 */;
cfg.members[1].priority=0
cfg.members[1].slaveDelay=120
cfg.members[1].hidden=false
rs.reconfig(cfg)
关于 MongoDB 中怎么搭建延时节点从库就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
向 AI 问一下细节

