共计 10141 个字符,预计需要花费 26 分钟才能阅读完成。
自动写代码机器人,免费开通
本篇文章给大家分享的是有关 InnoDB 中怎么插入数据,丸趣 TV 小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着丸趣 TV 小编一起来看看吧。
表空间 /Tablespace
假如,我想成为一名文学家,立志写一部长篇巨著,那么就需要把文字记录在纸张上。第一步就是从造纸厂购买两大卷未做裁切的白纸。相应的,在计算机中,所有数据也需要记录在磁盘、磁带、光盘等存储介质上进行长期保存。
这些介质被划分成文件,它们是存储数据的物理空间。
由于我买了两卷纸,而任何一卷都可以存储文字,因此每当我开始下笔时,都费劲心思难以抉择:到底应该记录到哪一卷中? 这对于有选择困难症的我来说苦不堪言。
于是,我计划请一个秘书,把要写的内容口述给他,通过他帮我文字誊写到具体的纸卷上,至于到底写在哪一卷上,我无所谓。
同理,用程序操作文件时,首先也需要指定文件路径。可是在数据库中,表是面向开发,而存储设备是面向运维。开发创建表时,很难确定一张表对应哪个文件。而运维也会根据实际情况动态为数据库添加文件。
表与文件的紧耦合严重制约了数据库使用的便利性,于是在文件与表之间增加一层表空间便顺理成章,它向上对接表,向下对接文件; 开发者只需在表空间中操作表,而具体存储由 Innodb 存储引擎根据表空间自动维护。
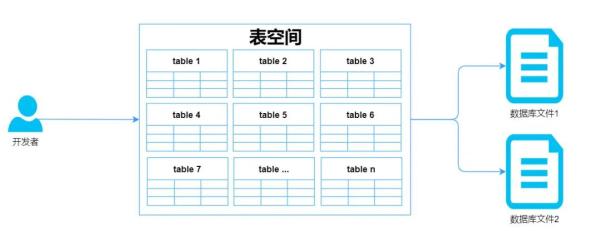
表空间是 InnoDB 存储引擎中逻辑结构的最高层,所有数据逻辑上都存储在表空间中。
表空间主要包括以下几种类型:
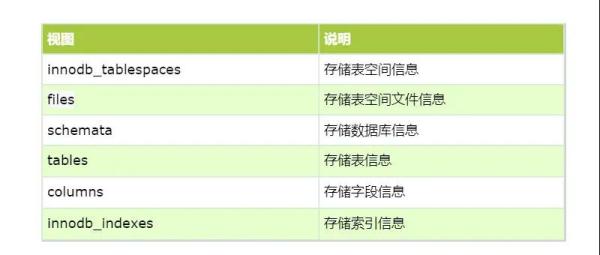
系统表空间 存储 change buffer, doublewrite buffer 以及与 innodb 相关的所有对象的元数据。如:表空间和数据库信息,表结构与字段信息等等。mysql8.0 中移除了原先用于存储表结构信息的.frm 文件,所有元数据都存储在此系统表空间中。系统表空间 information_schema 库中相关的核心视图如下:
假如数据库 world 中有一张对应表 user 表,测试如下:查询表所属表空间信息:select * from information_schema.innodb_tablespace where name= world/user (space: 表空间 id,name:表空间名)

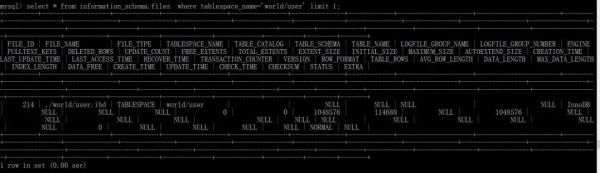
查询表空间对应的数据文件信息:select * from information_schema.files where tablespace_name= world/user (file_name:数据文件相对路径)
查询表对应的 id: select * from information_schema.innodb_tables where name= world/user

查询主键索引对应的根节点所在的页号(root page no) select * from information_schema.innodb_indexes where table_id=1269 and name= primary (page_no:B+ 树 root page no;name= primary 表示主键索引)

系统表空间也有对应的数据文件,这个文件默认为(windows 下)xxx\MySQL Server 8.0\Data\ibdata1。只有系统表空间可以指定多个文件,其它类型的表空间都只能指定一个数据文件。
独立表空间 每张表对应一个独立的表空间。通过配置 my.ini 中的参数:innodb_file_per_table= 1 启动独立表空间,否则,默认为系统表空间。5.6.6 之后此配置默认开启,因此默认为独立表空间。

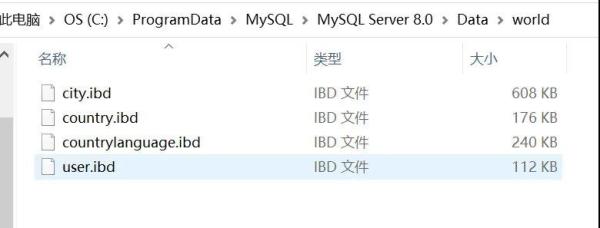
当创建表时,会自动为表创建一个对应表名的表空间,并在数据库目录下生成一个“表名.ibd”的表空间文件。如:在数据库 world 中创建 user 表结果如下
普通表空间 即通过“create tablespace 表空间名”手动创建的表空间。
临时表空间 存储临时表以及临时表变化对应的回滚段。默认的临时文件为(windows 下)xxx\MySQL Server 8.0\Data\ibtmp1
区 / 簇 /Extent
由于一卷原始的纸太过于庞大,展开后可能会铺满我豪宅地板十几层,甚至几十层,非常不方便使用,毕竟我 9 平米的豪宅还需要留出空间会客。最好的办法就是把这些纸张切割成一张张 A4 大小的数据页。
同理,一个磁盘或文件的容量也是非常可观,极其不便管理,因此 innodb 把文件划分成一个个大小相等的存储块,这些块也被称为页;

对于一部文学故事而言,只要通过页码就可以依次找到下一页,从而完整的读完这个故事。通常我们读完第一页时,会马上接着读第二页,但此时对应的书页如果零散的分布在卧室、厕所、客厅,将使阅读体验大大折扣。如果能把这些分散的书页合订成本,就可以极大地提高阅读的便利性。
根据局部性原理,cpu 在使用的数据时,下一步也会大概率使用逻辑上相邻的数据。因此为了提高数据读操作的性能,innodb 把逻辑上相临的数据尽可能在物理上也存储在相邻的页中; 为了实现这一目标,Innodb 引入了区 / 簇的概念;

一个区 / 簇是物理上连续分配的一段空间,extent 又被划分成连续的页,以存储同一逻辑单元的数据 (如下面的索引段、数据段)。一个区 / 簇,默认由 64 个连续的页(Page) 组成,每个页默认大小为 16K。
实际上,innodb 是先把文件划分成连续的区 / 簇,然后在区 / 簇内再划分出连续的页,从总体上看:一个文件即是微观上一系列连续的页组成,也是宏观上一系列连续的区 / 簇组成。知道一个页的页号和页大小就可以计算出此页在磁盘上的具体位置,同理知道一个页号就可以计算出一个区 / 簇的大小以及页所在的区 / 簇是第几个区 / 簇(它本身没有编号,但假设第一个区 / 簇为 0 号,可以知道它逻辑上是第几个)。
如果把页看作现实书本中的页,那么 extent 可以看作现实中的书本。
区的目的是为逻辑单元分配连续的空间,同时也用于管理区内的存储空间状态(如:区内哪些页已满,哪些还未使用,哪些包含碎片)。具体通过不同的区 / 簇链表来指明区本身的空间状态,以及通过 XDES Entry 中的 XDES_BITMAP 指明区内页的空间状态)。
### 段 /Segment
当年大刘写完三体第一本后,迟迟没有更新,但由于内容过于精彩,导致奥巴马又是写邮件,又是通过外交手段催更。为了避免中美关系受损,大刘如法炮制,又连续写了两本。
在逻辑上故事情连贯的这三本书总体上都叫三体,于是我们称这种具有相关性的多本书为一套。同理,innodb 把逻辑上有关联的区 / 簇归属为一个段。

为了使同一逻辑单元可以在物理上具有连续的存储空间,Innodb 提出的区的概念,但是 io 的最小操作单元为页,一次 io 并不能写满一个区,同时数据是可以擦除 (删除) 重写,因此必须记录区自身以及区内的空间状态:哪些区已写满,哪些区还未使用,哪些区还有碎片空间。
innodb 中把这些记录具有相关性区的存储空间状态的管理信息称为段实体,段实体所管理的区的总和称为段。段的目的是管理区的使用情况以及为数据分配空间时,提供空间存储状态。
段可以类似的看做现实中一套书中的套。
innodb 中数据是以 B + 树的方式组织,叶子节点存储关键字与行数据,非叶子节点存储关键字 (索引数据) 与页号。索引数据与业务行数据分别具有不同的数据结构,因此它们被分开存储,非叶子节点的索引数据存储在一个段中,叶子节点的业务数据存储在另一个段,对应的它们也分别存储在不同结构的区和页中。
数据逻辑结构如下:
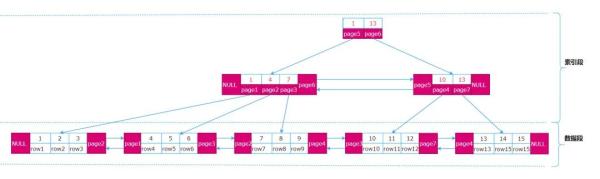
物理存储结构如下:
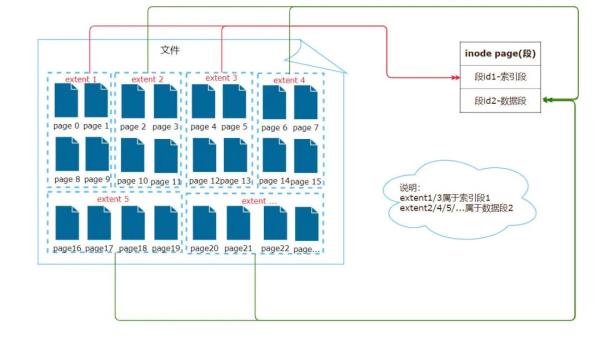
段是表空间的逻辑组成部分,用来存储具有相同意义的数据,如:B+ 对中的非叶子节点或 B + 树中的叶子节点。常见的段有数据段、索引段、回滚段等。
每创建一个索引就会创建两个段: 一个是数据段 (B+ 树对应的叶子节点),一个是索引段(非叶子节点)。对于聚集索引(一般是主键索引) 数据段存储的是索引关键字和业务行(所有字段); 对于非聚集索引,数据段存储的是索引关键字和主键; 如果通过非聚集索引查询,需要先通过 B + 树查出主键,再通过主键从聚集索引中二次查询具体的行, 这称为回表。下图:左边为二级索引(非聚集索引),右边为主键索引(聚集索引)
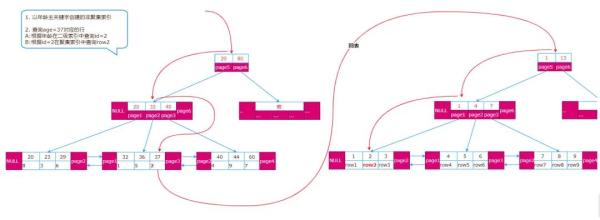
表数据是通过聚集索引组织存储,也即按主键索引创建的 B + 树存储数据,因此创建表时应该同时指定一个主键。如果没有指定主键,也没有创建唯一索引,表会默认创建一个自增的隐藏字段:row_id 做为聚集索引 B + 树的关键字段。因为是隐藏字段,所以这个字段只能回表查询时使用。
页 /Page
正如上面所说,页就像现实中一本书的书页一样,是 innodb 中 io 操作的最小单位。innodb 中的页类似于现实中书本的页。
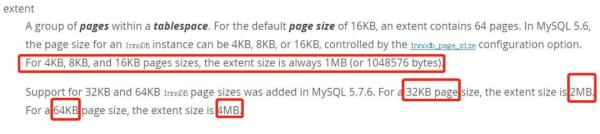
页的大小默认是 16KB; 可以通过 innodb_page_size 参数指定,可选项为:4KB、8KB、16KB、32KB、64KB; 当 page size 为 4、8、16KB 时,对应一个 extent 的 page 数量同步变化,以保证 extent(区 / 簇)大小保持 1M 不变。当 page size 为 32KB 或 64KB 时,extent 内的 page 数量保证不变,extent 同步变为 2M 和 4M;
每个页都有一个对应的从 0 开始的编号,这个编号叫做页号。因为表空间的数据文件会被划分成大小相等的页,所以知道页号,再根据文件的初始位置,就可以计算出页在磁盘中的准确地址。
同理,一张表对应一个聚集索引,而聚集索引元数据中指定了 root page 的页号,因此 Innodb 引擎可以根据页号和页大小计算出索引 B + 树 root page 的准确地址,从而对整个表数据进行操作。
page 主要用来存储业务相关的数据,但是为了管理内存分配而存在的 extent 和 segment 信息也需要 page 存储。innodb 根据 page 存储内容不同分以下几类:
FSP HDR 页:一个表空间可能对应多个数据文件,每个文件都有自己的编号。表空间是数据库中最顶层的结构,通过系统表空间中的元数据可以查询对应的表空间文件等元信息,却无法查询当前表空间对应的段、区等信息,因此也无法获取表空间中页的存储状态。
为了使表空间的物理存储有一个对外访问的入口,规定表空间中的 0 号文件的 0 号 page 页中存储表空间信息以及当前表空间所拥有的段链表的指针。
任何一个页都由页头、页身和页尾组成。
一个 page 默认 16KB,而段和区对应的指针数据量并不大,因此只需要部分头信息就可以维护。而剩下的大部分空间,则用来存储当前表空间拥有的部分发区实体信息。

页头:指明当前页号、类型和所属表空间。页尾:主要用于数据的校验。页身:这是页中用来存储数据的主要部分。
页身又分为表空间首页头信息区和业务数据区。FSP HEADER:(1):表空间信息:对应空间 id、表空间总页数等 (2):段信息:已写满数据的段实体所在页的链表指针、未写满数据的段实体所在页的链表指针 (指向的不是段实体而是段实体所在的页,一页存储 85 个段实体)。(3):碎片区 / 簇信息:空闲的碎片区 / 簇(XDES 实体本身,不是 XEDS 实体所在的页) 链表指针、未写满的碎片区链表指针、已写满的碎片区链表。这些区 / 簇信息不属于任何段,而属于表空间,用于给段下次申请空间时分配。
理论上一个区 / 簇会完整的分配给一个段,但一些区 / 簇创建后直接归属表空间,用做碎片区。为了减少浪费,只会把这些区中的部分页分配给一个指定的段。
例如:当你豪言万丈的宣布要写一部旷世巨著,并要求秘书给你五百页纸时,秘书很可能已经看透了一切,一面是是是的回应你,一面只会给你取 3 页纸,因为他认为你很可能 7 天憋不出 6 个字。同理,innodb 给某一个新创建的段分配空间时,并不是一开始就分配一个区 / 簇,而是从碎片区中先分配 32 页,只有这 32 页使用完,innodb 才认为这个段是一个大数据段,从而正式开始为其分配一个完整的区 / 簇。
数据部分:
FSP HEADER 中指向了段链表和碎片区链表,但这些只是链表指针,真正的区信息节点则存放在当前页的数据区。一个区 / 簇信息实体称为一个 XDES Entry(eXtent DEScript); 一页存储 256 个 XDES Entry。
XDES Entry 如上面图示,包含了段 id(如果分配给一个段)、碎片区链表中的下一个节点指针等。它不包含页信息,因为区 / 簇有对应的物理空间,它空间内的页就是拥有的页,因此无需在 entry 中指明。
细心的朋友会发现,XDES Entry 虽然是描述区 / 簇,但却没有指定区 / 簇的编号或地址,那么它到底对应物理空间中哪块区 / 簇呢?
区 / 簇本身没有编号,但区 / 簇像页一样,也是从文件第一个字节开始连续分配的。同时,每隔 256 个区 / 簇的第一个区的第一页就是这 256 个区 / 簇的索引页,即 XDES page。
而 XDES page 有 page No,因此就可以计算出此 XDES page 的地址,也即此 page 所有的区 / 簇的地址。紧接着的 255 个区 / 簇都有一个对应的 XDES Entry 存储在 XDES page 中,这些 XDES Entry 在此 page 中位置的偏移量,即为后面 255 个区 / 簇的偏移量,从当前 XDES page 所有区 / 簇位置以及对应的偏移量就可以计算出一个 XDES Entry 对应的区 / 簇的物理位置。
FSP HDR 页就像一个表空间的封面页,是整个表空间的入口页。
XDES 页:XDES 页即 eXtent DEScript 区 / 簇描述页的缩写,用来存储区 / 簇信息实体的页,即存储 XDES Entry 的页。它除了与 FSP 页中 FSP HEADER 不同外,其它内容一模一样。本质上首页也是一个 XDES 页,只是首页是整个表空间的第一页,因此它又兼职记录了表空间信息。
XDES Entry:存储了区自身信息的逻辑块。
因为一页 XDES 只能存储 256 个 entry,对应 256 个区,因此逻辑上每隔 256 个区,就需要一个 xdex 页来存储下一系列 256 个区的信息。
INODE 页:同区 / 簇对应的 Entry 信息一样,表空间只是指向了各种状态的段页 (非段实体) 链表,而未存储段信息本身。inode 页就是用来存储描述段信息 inode entry 的页。

一个 inode 页默认存储 85 条段实体,每个实体又指向了本段对应的不同状态的区 / 簇链表:未使用的区 / 簇链表、已写满的区 / 簇链表、未写满的区 / 簇链表。
Index 页 以上的页均是存储物理空间使用状态,并用于管理区 / 簇和段本身的页。index 页则是用于最终存储业务数据。innodb 中表数据是通过聚集索引组织存储的,而叶子节点存储在一个段中,非叶子节点存储在另一个段中,但最终都会存储在 Index 类型的页中。
index 页详细项如下图:

index 页页内存储结构如下图:
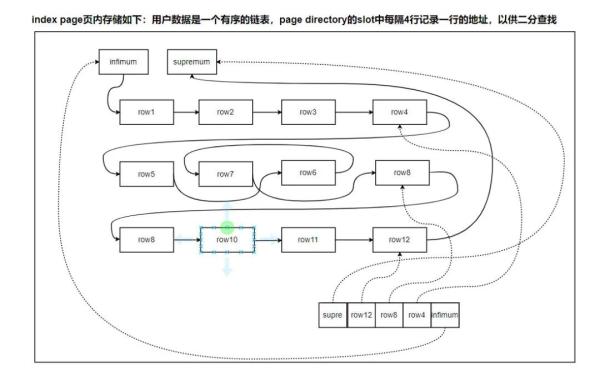
页内的业务数据是一个逻辑上按顺序排列的单向链表。页内有两条虚拟行,会别代表整个页中索引值最小的行和最大的行,即链表中第一行和最后一行,用来界定链表的范围。
另外,对于索引段,一页大概有 16250B 用来存储用户数据。一行包含一个 4 字节的 int 类型 key,一个指向叶子节点占 6 字节的页号,大概 6 字节的 row header,总共大概 16 字节。那么一页粗略的计算可以存储 16250/16 约为 1000 条。为了优化查询,每隔 4 - 8 行数据把这几行数据的第一行地址在存放在一个称为 slot 的 2 字节空间中,这些 slot 一起组成一个称为 Page directory 的数组中。
如图:数组最后一个 slot 存储第一行 infimum,倒数据第二个 slot 存储 row4,正序第一个 slot 存储最后一行数据 supremum。这样 page directory 数组就是一个有序的数组,可以通过一次二分查找算法快速定位数据块,然后在这个块中遍历找到最终符合要求的数据。
注意:由于用户行与页尾之间有空闲空间,而 slot 个数受页内行数影响而不固定,即 page dirctory 数组长度不固定,因此通过逆序向前追加的方式分配 slot。
整体结构
以上是表空间中不同对象各自的结构和数据信息,下面从整体的角度看一看各个组件是如何关联的。
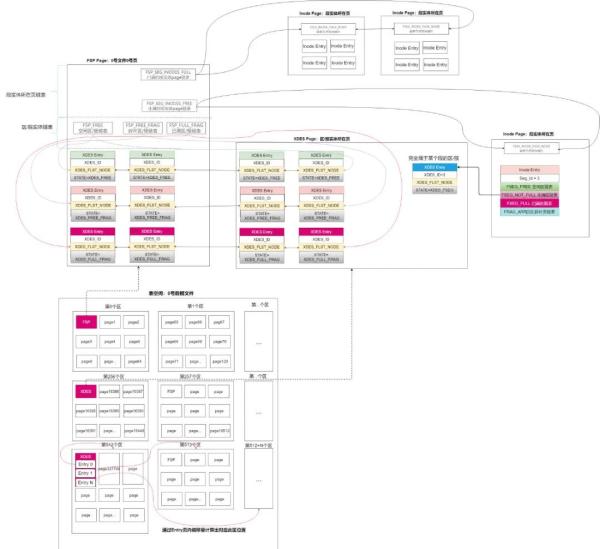
微观上,表空间文件从物理上分隔为大小相等且连续的页。
宏观上,表空间文件从物理上分隔为大水相乘且连续的区 / 簇。
0 号文件的 0 号页称为 FSP 页,即首页,可以假定为表空间的封面页。它存储了整个表空间其它组件的链表指针,是整个表空间的入口页。
从逻辑上,FSP 页通过两条线指向不同组件。(1):通过 FSP_SEG_INODES_FULL(已写满的段页链表)和 FSP_SEG_INODES_FREE(未写满的段页链表),指向段信息。段实体又通过 FSEG_FREE(空闲的区 / 簇链表)、FSEG_FULL(写满的区 / 簇)、FSEG_NOT_FULL(未写满的区 / 簇),指向属于本段的区 / 簇。(2):通过 FSP_FREE(空闲的区 / 簇链表)、FSP_FREE_FRAG(未写满的碎片区 / 簇)、FSP_FULL_FRAG(已写满的碎片区 / 簇),指向不属于任何段的区 / 簇。
每 256 个区 / 簇的第一个区 / 簇的第一页存储这 256 个区 / 簇的管理信息。0 号页因为特殊叫做 FSP 页,其它叫做 XDES 页。通过这个页号以及存储在其中的 Entry 位置偏移量,可以很容易的计算出这 256 个区在磁盘上的位置。因此即使 XDES Entry 中没有记录区 / 簇的编号或地址,也可以知道每个 Entry 管理的是哪个区 / 簇。
当 index 页中插入一条数据时,如果本页已满,则需要向此页所在的区 / 簇申请空间,如果此区 / 簇也满了,则向所在的段申请,如果段也满了,则会向表空间申请,表空间会通过操作系统向磁盘申请 3 个区 / 簇,并加入到 FSP 中的 FSP_FREE 链表中。然后再一级级分配,存储到其对应的链表中。
行 /Row
以上介绍的所有对象都是为了给业务数据分配一块用来存储的物理空间,到此终于可以在指定的页中记录业务数据。而 innodb 是基于行进行存储,下面简单的看一看行 Compact 格式的存储结构。

每条记录都包含一系列头信息,描述当前记录的存储状态如图。但是除了头信息外,则根据记录所在节点不同存储的数据也有所不同。
聚集索叶子节点,记录存储的是表中的业务行,除行数据本身外,还包含了事务 id,回滚段指针,以及在没有指定主键和唯一索引时还包含一个隐藏的 row_id。
非叶子节点针对的是 B + 树搜索,因此记录的是子节点的最小记录值以及子节点的页号。
B+ 树节点与 page 的关系
Innodb page 只是物理上的存储空间,相当于一本书的一页,仅仅是数据的载体。B+ 树节点是数据的逻辑结构,理论上它们没有必然的关系。可以在一个 page 页内存储一棵完整的 B + 树,也可以多个 page 页一起存储一棵完整的 B + 树,甚至可以把 page 页与 B + 树中的节点一一对应。
实际上 Innodb 中为了实现简单,B+ 树节点与 page 页是一一对应,以下是其简单的扩展过程。
假设有一个聚集索引 B + 树开始的样子如下:

向 B + 树中插入 16、17、18 三行数据如下(绿色部分):

向 B + 树继续插入 19 一行数据,原先的空间已满扩展如下(蓝色部分):

如果聚集索引使用的是自增的主键,那么数据是以追加的方式存储在每一页中,如果页已经存满,只需要重新分配一页空间继续追加即可。
如果聚集索引使用的是无顺序的列如 uuid,由于 B + 是一个逻辑上有序的集合,那么向 B + 树中插入数据就很可能插入到原先已经满了的 page 页中,就会导致原来的页进行分裂。会像向数组中插入数据一样先进行移动,为新数据腾出空间。因此建议使用有序的列做聚集索引。

如何一步步存储一条数据
经历了千辛万苦,终于可以从头到尾插入一条数据,一探 innodb 如何一步步把数据存储到文件中。妹妹们估计已经听的如痴如醉,想想都开心,我可真是个小机灵鬼。
伸伸懒腰,甜甜的望向妹妹们。
哎,人呢? 我是穿越到平等空间了吗?
算了,善始善终,我就讲给自己听,迷倒不了别人,我还不信迷倒不了自己。
在数据库 world 中创建表 user
CREATE TABLE user ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(10) DEFAULT NULL, age int(11) DEFAULT NULL, gender smallint(6) DEFAULT NULL, create_time date DEFAULT NULL, PRIMARY KEY (id) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4innodb 向系统表空间的 information_schema 库的 tables 和 columns 中存入表结构信息


创建表空间 同时创建独立表空间 world/user 以及对应的数据文件 world/user.ibd,并更新到 information_schema.innodb_tablespaces 中

同步更新表空间所对应的文件信息到 information_schema.files 中

规定表空间 0 号文件即 world/user.ibd 文件的 0 号页为表空间的封面页。
创建聚集索引 如果指定的主键或唯一索引,则使用指定的列创建聚集索引,否则使用隐藏列 row_id 创建聚集索引,并存储到 information_schema.innodb_indexes 中

为索引创建两个段:索引段 (非叶子节点) 和数据段(叶子节点),并把段信息存储到表空间封面页的段链表中。
为索引创建第一页即 Root Page,把段信息记录在 Root Page 的段链表中,从而管理本 B + 树的段信息。同时把 Root PageNo 记录到 information_schema.innodb_indexes 中,如上图。从页使逻辑表与物理存储关联起来,这个 Root Page 相当于索引的封面。
插入数据 向表中插入一条数据如下
insert into world.user(name,age,gender,create_time) values(木叶潇潇 ,18,1,now())从 sql 中提取数据库名和表名,从 information_schema.innodb_tables 中查出表 id

根据表 id,从 information_schema.innodb_indexes 中查出表对应的聚集索引的 Root Page No 为 4。

通过 Root Page No 4 计算出 Root Page 的物理地址。根据 Root Page 中指定的段信息,向 Root Page 中插入索引数据,向数据段对应的页中插入数据行,并关联两种类型的页。
如果一页空间不足,会计算出当前页所在的区 / 簇并向其申请空间,区 / 簇则会根据 XDES Entry 中的 bitmap 查询空闲的页并进行分配。如果区 / 簇也没有空闲空间,则会一级一级向上面的段、表空间、操作系统申请所需空间。
申请到的表空间会存储在各自对应的链表中(如:表空间申请到的空间会存储在对应的 FSP_FREE 链表中)。
在页分配或扩展时,为了保证通过 innodb_indexes 中的 Root Page No 能找到它,Root Page 物理空间与 B + 树对应的 Root 节点保持不变, 即页号不变,永远是页号为 4 的那块空间。
当 B + 对应的物理页不断变化时,为了保证树的平衡,会产生新的 Root 节点,为了保持 Root 页不变,innodb 是通过交换的方式,把新的 Root 节点数据复制交换到原来的 Root Page 页,这样就可以保证 Root Page 永远不变,即保证表与物理空间的关联永远不会断开。
总结
表空间是数据库中的逻辑结构,它解耦了表、索引等与文件的关联。
段也是一个逻辑结构,它让具有具体相同逻辑含义和相同存储结构的数据归为一组,方便管理。
区是物理存储结构,对应大磁盘中真实的物理空间。它从文件第一个字节开始按相同大小划分,并通过 XDES Entry 在逻辑上把区串联起来。通过 XDES Entry 所在页以及页内偏量可以计算出 XDES Entry 与它管理的物理空间区的关系。
页是物理存储 IO 操作的最小单元。它也是从文件第一个字节开始按相同大小划分。表是通过索引的方式组织数据,聚集索引元数据中存储了此表对就的 Root page No。页是有编号的,通过编号就可与物理空间建立关联。
段、区都是为了管理空间的存储状态,为页分配空间服务,真正的查询只需要通过 Page No 和 B + 树中各级节点的关联关系就可以操作整个表物理空间上的数据。
行是最终存储业务数据的物理单元。默认一页 16K,可以存储大概 1000 多行索引数据(非叶子节点),或者 20 行甚至更多的业务数据(叶子节点)。页之间通过 B + 树的“二分找查(假设为多分)”算法快速定位数据,页内则通过 Page Directory,把多行分一组,一组对应 Page Directory 有序数组中的一个 slot,这样可以在页内进行一次“二分查找”优化。
为了记录行本身的状态,一条记录 innodb 会增加额外的记录头信息。如果是叶子节点,还会增加:row_id(隐藏的主键)、trx_id(事务 id)、回滚指针等附加字段。
以上就是 InnoDB 中怎么插入数据,丸趣 TV 小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注丸趣 TV 行业资讯频道。
向 AI 问一下细节










